Distributed Execution of JMeter (AWS Fargate + Docker)
Table of Contents
Advanced - This article is part of a series.

With this article we conclude the distributed JMeter series, in this case using containers. There are many variants of this modality since we could use a great variety of container-based platform for Kubernetes administration and orchestration as:
- Amazon Elastic Kubernetes Service (EKS)
- Azure Kubernetes Service (AKS)
- Google Kubernetes Engine (GKE)
- Rancher, etc.
We can also use non-Kubernetes versions as:
- Amazon Elastic Container Service (ECS) at AWS.amazon.com/ecs/
- Azure Container Instances (ACI) at Azure.microsoft.com/services/container-instances/
- Google Cloud Run at Google.cloud.run/ etc.
For this particular example, we will use the solution AWS Elastic Container Service (ECS) with the service Fargate.
When would it be prudent to undertake the effort? #
As I mentioned in my previous publications JMeter distributed locally and JMeter distributed publicly, I advise you to use this approach if you need to perform a load or stress test between 8,000 and 25,000 threads or virtual users. This is due to the investment of time and effort required to enable this approach. Of course, this modality can be expanded much beyond 25k threads. However, I recommend using EC2 instead of Fargate and requesting support for monitoring instances and results in real-time.
How it works? #
This architecture no longer functions in the master-slave mode. The main reason is that the communication mechanism between master and slaves, RMI (Java Remote Method Invocation), is not very efficient for large volumes and could generate bottlenecks (ironic). Each running container will be a load generator, and to generate the image of the container, we will base ourselves on the alternating flow of the guide JMeter + Docker.
Once the image is available in the AWS repository, we can define a task linked to that image. To execute it, execution will be done via Fargate and we can scale up to a maximum of 50 tasks. But remember, each task would be an active container or a load generator, so there are 50 load generators available.
After the execution, the JTL result files and JMeter log will be copied to S3 so you can download them, process them or archive them as evidence of the execution. Here you can find an example similar to what we are going to follow next but it is done through command line and is in English.
Recipe for cooking #
1. Clone the Repo #
First we need to clone the following repository, to get the files needed to build our Docker image:
git clone https://github.com/daeep/JMeter_Docker_AWS.git
cd JMeter_Docker_AWS
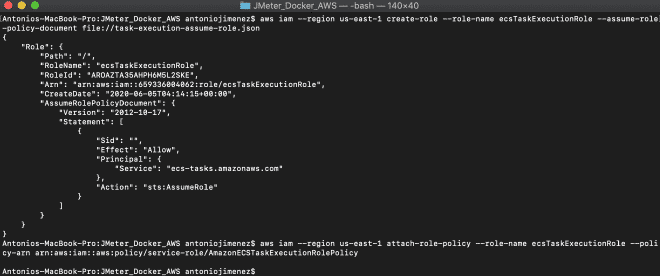
2. Generate the IAM role #
We will generate a specific role to execute tasks in Fargate, this role is called ecsTaskExecutionRole. This role can be generated through command line or by the AWS management console. I recommend installing and configuring the AWS CLI CLI to create this role using the file task-execution-assume-role.json included in the repository we downloaded.
aws iam --region us-east-1 create-role --role-name ecsTaskExecutionRole --assume-role-policy-document file://task-execution-assume-role.json
aws iam --region us-east-1 attach-role-policy --role-name ecsTaskExecutionRole --policy-arn arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy
As you can see, I am working in the region us-east-1.
3. Add the S3 Bucket and AWS Credentials to the Docker file #
We need to modify and adapt our Dockerfile located in the directory JMeter_Docker_AWS, which is part of this project. This project contemplates saving the result files in S3, although we could also save the results in InfluxDB or ElastiSearch to be consumed by Grafana or Kibana respectively. To save the result files in S3, we need to create a bucket and include our credentials on lines 18-20 of the Dockerfile, these credentials could be the same as those used by the AWS CLI if you granted it administrator permissions.
18 ENV AWS_ACCESS_KEY_ID #####################
19 ENV AWS_SECRET_ACCESS_KEY #################
20 ENV AWS_DEFAULT_REGION #################### <-- can be the region (us-east-1)
Finally, we need to modify lines 53 and 54 with the bucket name where the files will be stored. Here is a Spanish guide for creating buckets. If you do not want to save the JTL result file and the JMeter log bitstream, you would need to delete lines 18-20 and 49-54. However, I do not recommend it.
53 && aws s3 cp ${JMETER_HOME}/result-${PUBLIC_IP}-${LOCAL_IP}.jtl s3://nombre-del-bucket/ \
54 && aws s3 cp ${JMETER_HOME}/jmeter-${PUBLIC_IP}-${LOCAL_IP}.log s3://nombre-del-bucket/
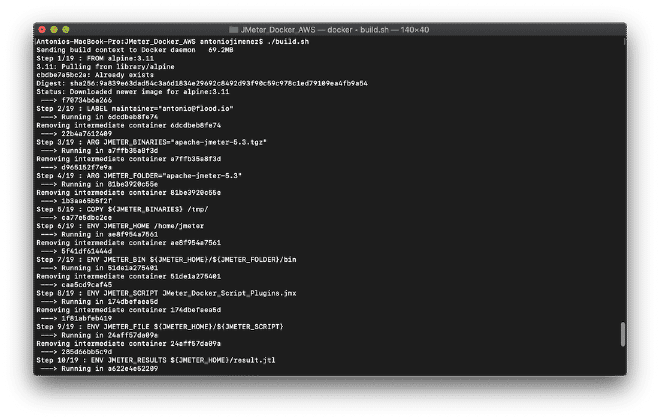
4. Build the Docker file #
We will compile our image before pushing it to the repository. We can do this by executing the shell script ./build.sh located in our directory or by using the command: docker build -t jmeter-docker ., which is very similar to the publishing flow of JMeter + Docker. This project is also prepared to build the image with our local binaries, but now it will copy the JMX script inside the container (modify line 13). If you need support files like CSV or images, add them similarly to lines 11, 13, 14, and 17.
11 ENV JMETER_HOME /home/jmeter <-- Carpeta local interna
...
13 ENV JMETER_SCRIPT JMeter_Docker_Script_Plugins.jmx <-- Nombre de tu script local
14 ENV JMETER_FILE ${JMETER_HOME}/${JMETER_SCRIPT} <-- Archivo final interno
...
17 COPY ${JMETER_SCRIPT} ${JMETER_FILE} <-- Copia el archivo local dentro del contenedor
5.- (Optional) If you need more memory #
Once our image is compiled, we can run it locally to validate that it actually works. To do this, you can alternate lines 21 or 22, which contain different values for JVM_ARGS. It should be noted that this script is parameterized following the instructions described parameters. Remember to recompile before running if you modified this value and finally to launch it we can use the shell script ./run.sh.
21 ENV JVM_ARGS="-Xms2048m -Xmx4096m -XX:NewSize=1024m -XX:MaxNewSize=2048m -Duser.timezone=UTC" <-- Suficiente para algunos cientos de usuarios concurrentes
22 ENV JVM_ARGS "-Xms256m -Xmx1024m -XX:NewSize=256m -XX:MaxNewSize=1024m -Duser.timezone=UTC" <-- Suficiente para algunas decenas de usuarios concurrentes
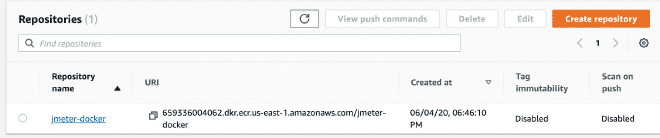
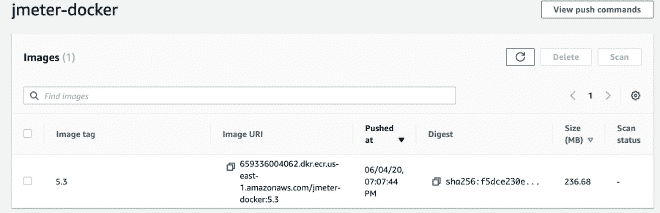
6.- Create the ECS repository and upload Docker image #
We continue by creating an AWS ECS repository, it’s not complicated. But you can also consult the steps here once you have the repository ready. We will upload the image with the following commands:
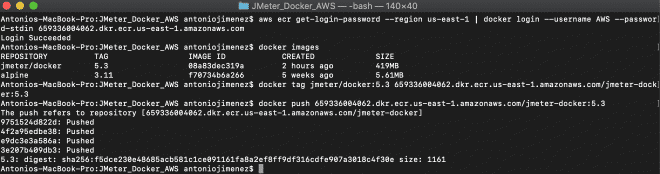
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin 659336004062.dkr.ecr.us-east-1.amazonaws.com
docker tag jmeter-docker:latest 659336004062.dkr.ecr.us-east-1.amazonaws.com/jmeter-docker:latest
docker push 659336004062.dkr.ecr.us-east-1.amazonaws.com/jmeter-docker:latest
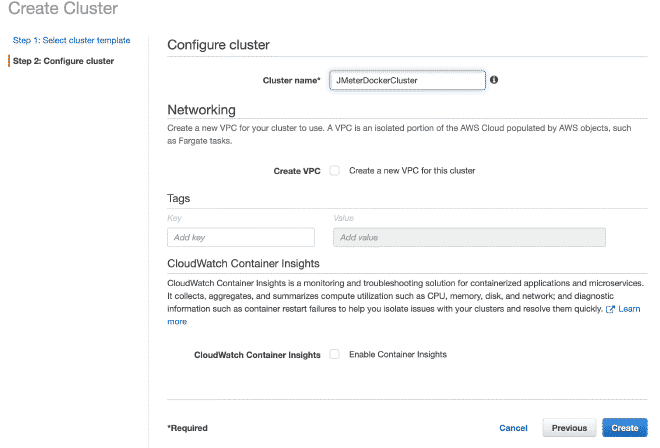
7. Create a Fargate Cluster #
Now we will create a Fargate cluster. I believe you can reproduce the steps by following the images.


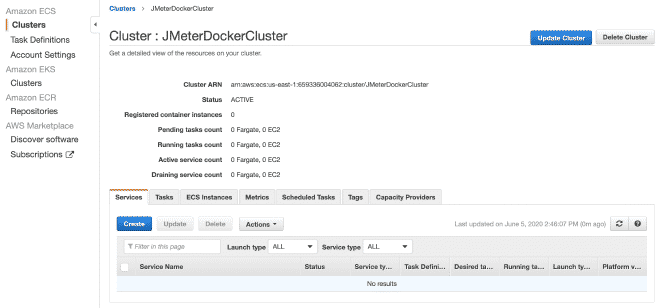
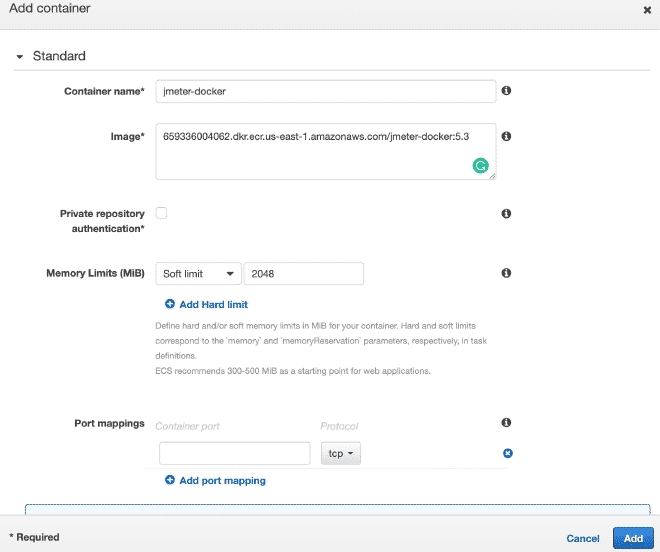
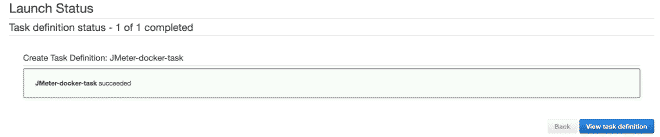
8. Defining Tasks in Fargate #
We will define a new task, and I believe it is possible to continue only with images.

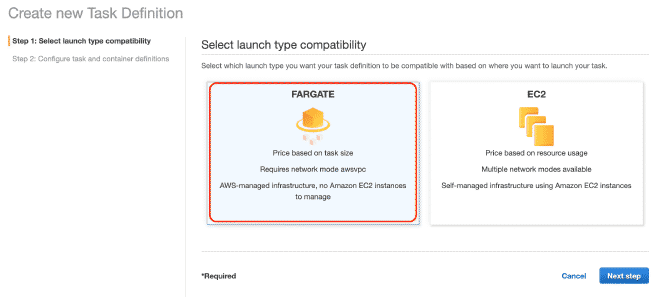
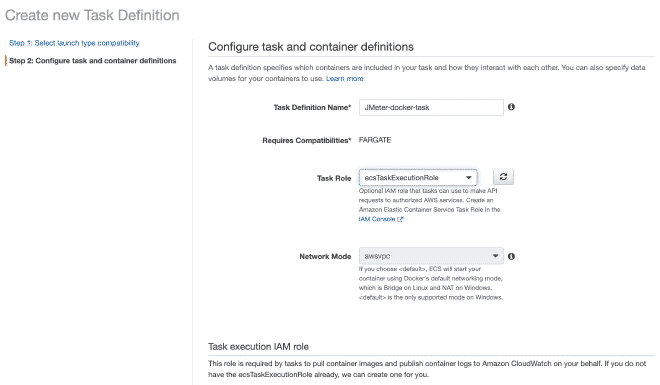
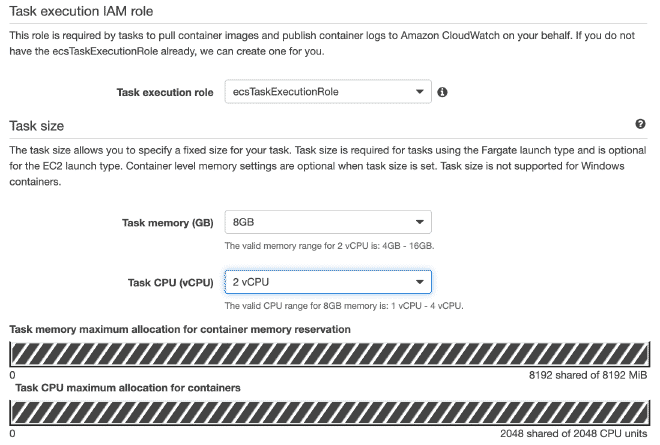
Remember that the values for CPU and Memory, as well as the gentle memory limit are configurable and I recommend starting with a few threads to not quickly exhaust the resources and fail the test.
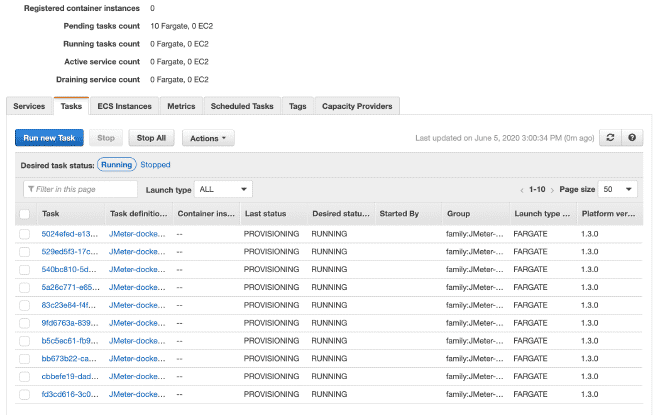
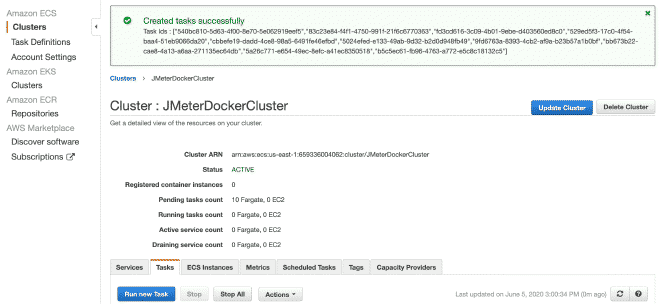
9. Execute Tasks #
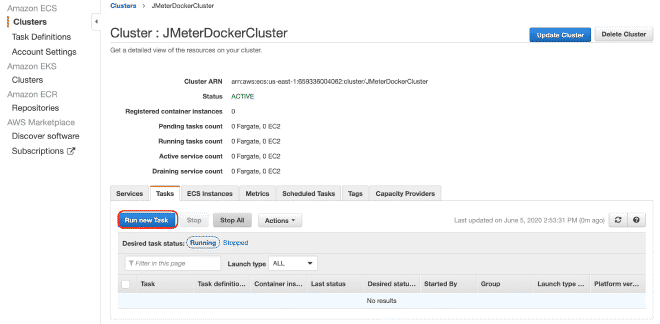
Finally, we will execute the(s) task(s) within our Cluster. The maximum number of tasks per cluster is 10. If we want to run more tasks, we will need to generate more clusters. The advantage is that the job has already been defined, it will be very easy to run it in multiple clusters. I understand there are a total limit of 50 tasks, which means 5 clusters running up to 10 tasks each maximum, but also you can request increases in limits, although if we require more computing power, I recommend using EC2 instead of Fargate.
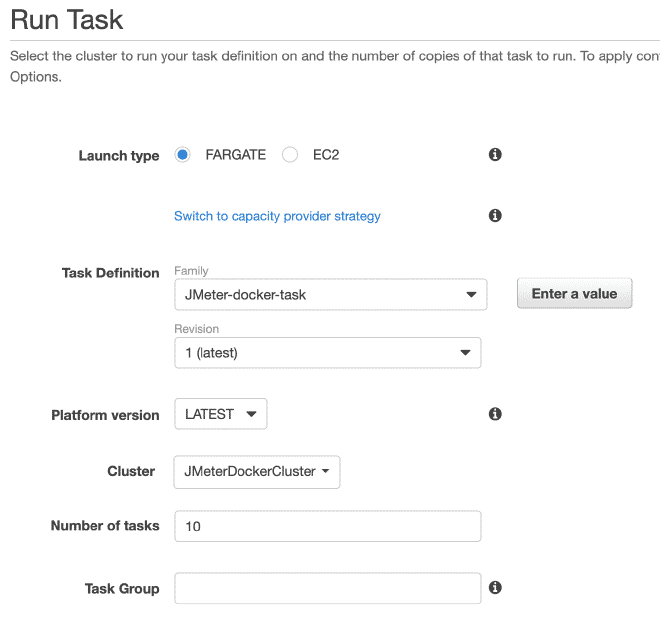
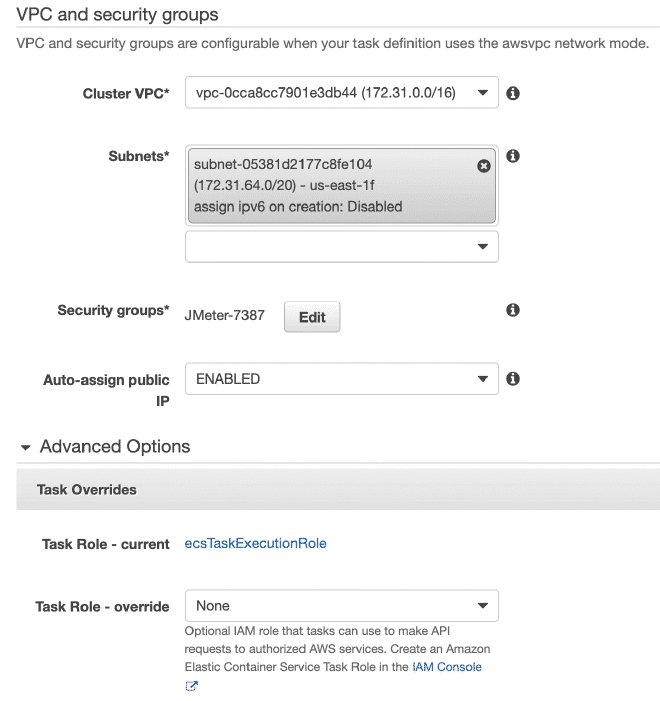
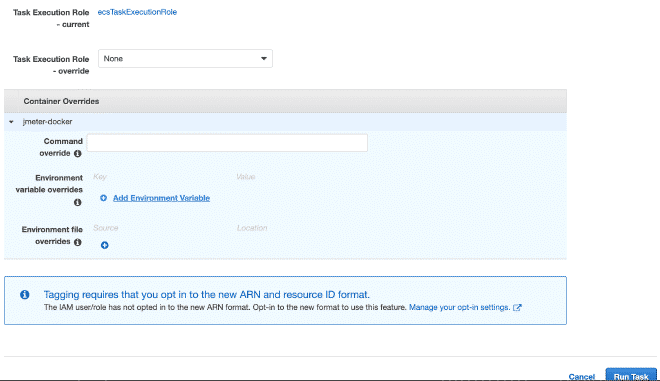
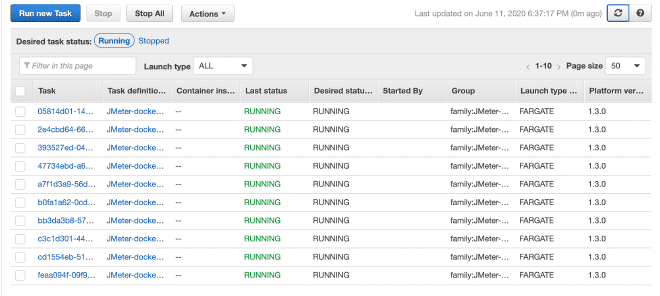
In the execution section of the task, we can define environment variables. Therefore, if we want to overwrite or cancel any variables such as users, ramp, or duration, we can do it here.
Conclusion #
I understand that there are many steps and they may seem difficult, especially if you’re new to AWS or ECS. Just as a reason for this, I decided to publish the Docker section before explaining the AWS section, hoping my effort to simplify the content will help them reproduce it. This solution is extremely versatile and could be used with any other container orchestration platform for execution and obtaining similar results. It should also be noted that we were able to resolve some sections using Docker compose or ec2_param in YAML format via command line, but the intention was to simplify the content. I hope they can replicate this schema without hesitation contacting us if they need our help.
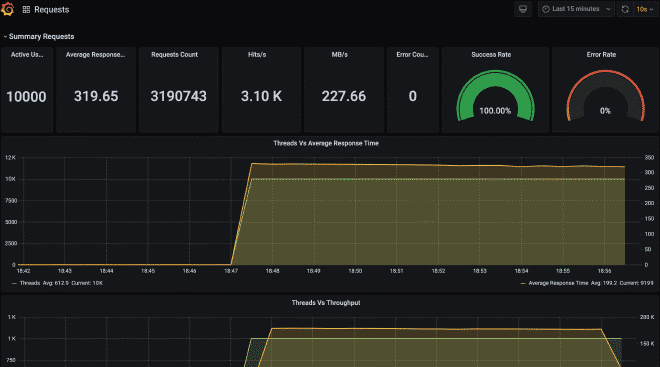
Finally, I leave you with how the files would look in S3 and the Grafana dashboard with the information from this execution.
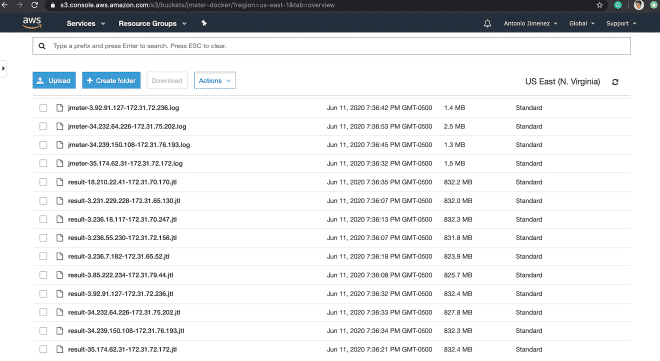
https://jmeter-docker.s3.amazonaws.com/result-35.174.62.31-172.31.72.172.jtl