

XPath Extractor
Table of Contents
Intermediate - This article is part of a series.

What is XPath? #
XPath is a query language used to find and select specific information in XML documents. XPath’s syntax is based on the path notation used in file systems, making it easy to learn and use for those familiar with that notation. The history of XPath is closely tied to the development of XML. XPath was developed by the World Wide Web Consortium (W3C) as part of the XSLT (Extensible Stylesheet Language Transformations) specification, which was published in November 1999. XSLT is a language used for transforming XML documents into other formats, such as HTML or plain text.
XPath was designed to allow developers to access specific information in XML documents and provide an efficient way to search and select elements and attributes. XPath is widely used in applications that work with XML, such as XSLT transformation processors, web browsers, and database management systems that use XML to store and retrieve data. Its simple syntax and ability to precisely select data make it a powerful and versatile tool for analyzing and manipulating data.
What is XML? #
XML stands for eXtensible Markup Language (Extensible Markup Language). It is a markup language used to create structured documents. XML was created as a standard for creating documents that could be read both by humans and machines. The history of XML dates back to the 1990s, when the World Wide Web began to gain popularity and it became necessary to have a markup language that allowed the creation of structured documents and could be interpreted by different systems and applications. At that time, the most commonly used markup language was HTML, but this was not sufficient for the needs of the era. In 1996, the World Wide Web Consortium (W3C) initiated a project to create a markup language that could be used for any type of document. This project was led by Jon Bosak, who proposed the name XML and designed the syntax of the language. XML was officially presented in February 1998 and was adopted rapidly as a standard by the industry.
Since then, XML has been used in a wide variety of applications, including data representation in web-based applications, communication between heterogeneous systems, and the creation of structured documents in various industries such as book editing and scientific publications. XML has evolved over time and new extensions and tools have been created for its use.
<?xml version="1.0" encoding="UTF-8"?>
<book>
<title>El guardián entre el centeno</title>
<author>J.D. Salinger</author>
<publisher>Alianza Editorial</publisher>
<year>1951</year>
<genre>Ficción</genre>
<price>10.99</price>
</book>
How does XPath work in JMeter? #
In JMeter, the XPath Extractor is a Post-Processor that allows you to extract specific values from an XML response. To do this, we need to follow these steps:
- Add an element HTTP Request or Dummy Sampler to your test plan of JMeter to make an HTTP request and receive an XML response.
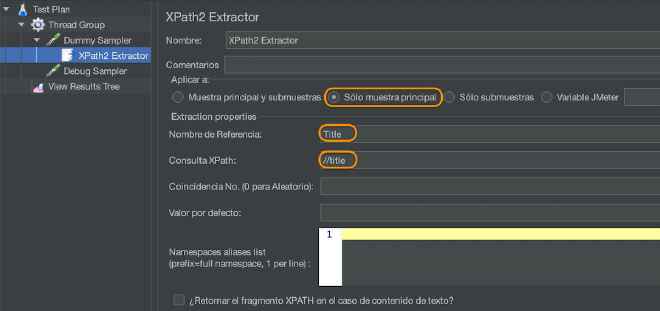
- Add an extractor XPath or XPath2 Extractor to the element mentioned above, which will be responsible for extracting specific values from the XML response.
- Configure the required fields in the post-processor XPath or XPath2 Extractor as shown in the following table:
| Attribute | Description | Required |
|---|---|---|
| Name | Descriptive name for this element that is displayed in the tree. | Not |
| Apply to | Useful when used with mappers that can generate sub-samples, such as HTTP sampler with embedded resources, Mail Reader or transaction controller generated samples. Main sample only: applies only to main sample Sub-samples only: applies only to sub-samples Main and sub-samples: applies to both Variable name used in JMeter: the extraction will be applied to the content of the named variable. The XPath match is applied to all samples that qualify, and all matching results will be returned.< | Yes |
| Return complete XPath fragment instead of text? | If selected, returns the fragment instead of the text. For example, //title returns “<title>Apache JMeter</title>” in place of “Apache JMeter”. In this case, //title/text() returns “Apache JMeter”. | No |
| Name of variable created | The name of the JMeter variable where the result will be stored. | Yes |
| XPath Query | Query element using XPath 2.0 language. Can return multiple matches. | Yes |
| Number of Matches (0 for random) | If the XPath query has many results, you can choose which to extract as variables: 0: means random (default) -1: means extract all results, will be named as <variable name>_N (where N is from 1 to number of results) X: means extract the result X (in case X is greater than the number of matches, nothing will be returned. The default value will be used). | No |
| Default Value | Default value returned when no match found. Also returns if node does not have a value and option for fragment is not selected. | No |
| List of alias namespaces | List of aliases you want to use to analyze the document, one line per declaration. You must specify them as prefix=namespace. This implementation facilitates using namespace in comparison with previous version of XPathExtractor. | No |
Example:
<?xml version="1.0" encoding="UTF-8"?>
<book>
<title>El guardián entre el centeno</title>
<author>J.D. Salinger</author>
<publisher>Alianza Editorial</publisher>
<year>1951</year>
<genre>Ficción</genre>
<price>10.99</price>
</book>
We can extract the following values using XPath:
/book/title //El guardián entre el centeno
/book/author //J.D. Salinger
/book/publisher //Alianza Editorial
/book/year //1951
/book/genre //Ficción
/book/price //10.99
What is an XPath Query? #
An XPath query is an expression written in the XPath language that is used to select specific nodes from an XML document. XPath expressions are composed of a series of location steps that specify how to navigate the XML document and select the desired nodes. For example, a simple XPath query like //title would select all title nodes in the XML document, while a more complex query like //book[@category='science']/title would select only the titles of books that belong to the science category.
What other examples of usage could XPath extractor have? #
Suppose we consider a more complex example like the following:
<root>
<item>
<name>John Doe</name>
<age>35</age>
<address>
<street>123 Main St</street>
<city>Anytown</city>
<state>WA</state>
</address>
<phoneNumbers>
<item>
<type>mobile</type>
<number>555-551-1234</number>
</item>
<item>
<type>home</type>
<number>555-552-5678</number>
</item>
</phoneNumbers>
<email>john.doe@example.com</email>
</item>
<item>
<name>Peter Doe</name>
<age>34</age>
<address>
<street>123 Second St</street>
<city>RacconCity</city>
<state>TX</state>
</address>
<phoneNumbers>
<item>
<type>mobile</type>
<number>555-553-1234</number>
</item>
<item>
<type>home</type>
<number>555-554-5678</number>
</item>
</phoneNumbers>
<email>peter.doe@example.com</email>
</item>
<item>
<name>Rick Doe</name>
<age>36</age>
<address>
<street>123 Third St</street>
<city>Springfield</city>
<state>NJ</state>
</address>
<phoneNumbers>
<item>
<type>mobile</type>
<number>555-555-1234</number>
</item>
<item>
<type>home</type>
<number>555-556-5678</number>
</item>
</phoneNumbers>
<email>rick.doe@example.com</email>
</item>
</root>
For this example, suppose we want to evaluate and extract the following data:
| XPath Expression | result |
|---|---|
| //name | All name elements John Doe, Peter Doe, Rick Doe. |
| //item[1]/name | The name element of the first object John Doe. |
| //item[2]/age | The age property of the second object 34. |
| //item[3]/email | The email property of the third object rick.doe@example.com |
| //item[1]/address/street | The street property of the address of the first object 123 Main St. |
| //item[2]/address/city | The city property of the address of the second object RacconCity. |
| //item[3]/address/state | The state property of the third NJ object’s address. |
| //item[2]/phoneNumbers/item[type=‘mobile’]/number | The mobile phone number of the second object 555-553-1234. |
| //item[3]/phoneNumbers/item[type=‘home’]/number | The landline phone number of the third object 555-556-5678. |
| //phoneNumbers/item[type=‘mobile’]/number | All mobile phone numbers 555-551-1234, 555-553-1234, 555-555-1234. |
| count(/root/item) | The number of objects 3. |
| sum(//age) | The sum of all ages 105. |
| //name | //email | All names and email addresses. |
| (//phoneNumbers/item[type='mobile']/number)[1] | The first mobile phone number 555-551-1234. |
| (//phoneNumbers/item[type='home']/number)[2] | The second home phone number. |
| //*[starts-with(name(), 'a')] | Returns fields that begin with the letter a. |
| //phoneNumbers/item[starts-with(type, 'h')]/number | Returns phone numbers whose type begins with h - home. |
| /root/item[not(starts-with(email, 'john'))]/email | All emails that do not begin with John. |
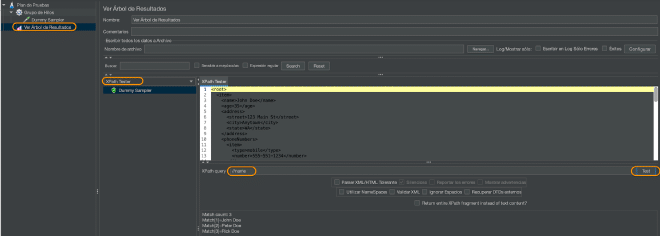
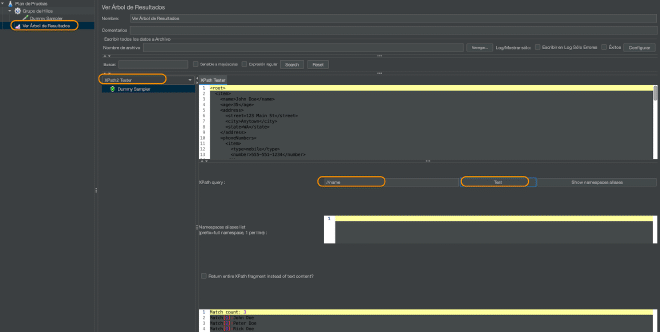
To evaluate these statements, I recommend using a View results tree receiver and using the view in XPath Tester and entering the statement in the XPath Expression field and clicking on the Test button.
What is XPath 2 in JMeter? #
In JMeter, XPath 2 is implemented using the library Saxon, which is a version of XPath 2 and XSLT 2. Starting from version 5 of JMeter, we only need to use XPath 2. The main difference between XPath and XPath 2 in JMeter is that XPath 2 is a newer version of the XPath query language and offers additional features not available in the previous version. One of the significant improvements in XPath 2 is support for complex data types, which allows working with more structured data in queries. XPath 2 also provides a series of additional functions to manipulate and transform data, such as sorting and grouping query results.
Here are some XPath 2 examples:
| XPath 2 Expression | result |
|---|---|
| //item[position() = 1] | Selects the first item element. |
| //phoneNumbers/item[type = 'home']/number | Selects the phone number from all elements that have a type attribute equal to home. |
| //address[state = 'WA']/city | Selects the city from all addresses that have a state attribute equal to WA. |
| //item[ends-with(email, 'example.com')]/name | Selects the name of all item elements whose email address ends with example.com. |
| //item[name = 'Peter Doe']/address/city | Selects the city from the address of the item item with the name Peter Doe. |
| //phoneNumbers/item[matches(number, '.*1234')]/type | Selects the type of all items whose phone number contains the sequence 1234. |
| //item[age >= 35]/name | Selects the name of all items whose age is greater than or equal to 35. |
| //item[not(address/state = 'TX')]/email | Selects the email address for all items whose status is not TX. |
| //item[phoneNumbers/item[type = 'home'] and phoneNumbers/item[type = 'mobile']]/email | Selects the email address for phones with type home or mobile. |
Conclusion #
XPath 2 Extractor is a very powerful tool for extracting values, multiple values, evaluations or execution of functions from the values to satisfy one or more criteria. Remember always to practice before developing your sentence or expression. It’s good to verify the criteria with different types of responses to obtain conclusive results. Practice is needed, until next time!