

JMeter (Elasticsearch + Kibana)
Sommaire
avancé - This article is part of a series.

Qu’est-ce que Elasticsearch? #
Elasticsearch est un moteur de recherche et d’analyse distribué qui sert également d’outil open source. L’écosystème comprend une variété de types de données, y compris textuelles, numériques, géospatiales, structurées et non structurées. Elasticsearch a été développé dans Apache Lucene et présentée par Elasticsearch N.V. (maintenant connue sous le nom d’Elastic) en 2010. Noté pour sa simple API RESTful, son caractère distribué, sa vitesse et sa scalability, Elasticsearch est la composante principale du Stack Elastic, une collection de logiciels open source destinés à l’ingestion, à l’enrichissement, à la sauvegarde, à l’analyse et à la visualisation des données. Le terme communément utilisé comme ELK Stack (pour Elasticsearch, Logstash et Kibana), le Stack Elastic maintenant inclut une grande variété d’agents appelés Beats qui envoyent les données vers Elasticsearch.
text extrait de ici et je recommande d’y visiter pour connaître toutes les bénéfices de Elasticsearch.
Qu’est-ce que Kibana ?
Kibana est une application frontale open source qui se trouve sur le Elastic Stack et fournit des capacités de visualisation de données et de recherche pour les données indexées dans Elasticsearch. Populairment connue sous le nom du outil frontale pour le Stack Elastic (précédemment appelé ELK Stack par Elasticsearch, Logstash, et Kibana), Kibana également agit comme une interface utilisateur pour surveiller, gérer et sécuriser un cluster Elasticsearch ; elle est aussi un hub centralisé pour les solutions intégrées développées dans le Stack Elastic. Développé en 2013 par la communauté de Elasticsearch, Kibana a devenu l’œil sur toute l’offre du Stack Elastic offrant une porte d’entrée aux utilisateurs et aux entreprises.
Text extrait de ici ( https://www.elastic.co/es/what-is/kibana) et je recommande d’y visiter pour s’informer sur tous les avantages de Kibana.
Comment fonctionne l’intégration de Elasticsearch et de Kibana avec JMeter ? #
La intégration est assez simple mais pas très populaire. Comme la publication précédente JMeter avec InfluxDB et Grafana, nous utiliserons le composant de liste arrière Backend Listener, mais modifié et adapté pour envoyer les données à Elasticsearch. Le fichier JAR peut être téléchargé ici, ce plugin a été créé par Anthony Gauthier basé sur le code de la liste arrière backend original. Ce composant de récepteur envoie les données à Elasticsearch via des requêtes HTTP asynchrones et obtient les résultats dans format JSON par JMeter.
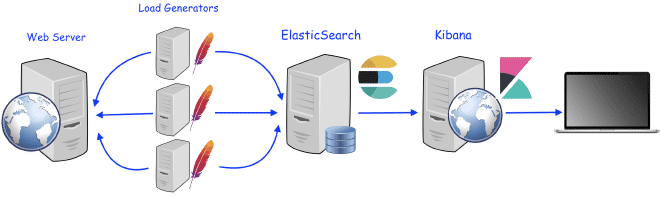
Le récepteur enverra tous les résultats décrits ici vers ElasticSearch, quel que soit le niveau de test plan ou la groupée spécifique. Les résultats seront transmis à ElasticSearch jusqu’à un maximum de 5000 objets, chaque objet peut contenir plusieurs mesures ou valeurs. Les données sont émises en requêtes HTTP POST au serveur Elasticsearch une fois que nous avons validé que les données existent sur l’index choisi, et on peut construire un dashboard dans Kibana ou même dans Grafana pour afficher les résultats. N’inquiètez pas si vous ne savez pas comment le faire ; il y a de nombreux dashboards prédéfinis disponibles dans la communauté de Kibana et Grafana pour visualiser les résultats de JMeter.
Qu’est-ce qu’on a besoin ? #
On a besoin d’une instance de Elasticsearch, je recommande d’utiliser la version cloud trial du Elastic ( https://www.elastic.co/cloud/elasticsearch-service/signup?elektra=downloads-overview&storm=elasticsearch) qui vous donne 14 jours d’un cluster composé de (ElastiSearch, Kibana et Recherche Enterprise), ce qui est plus qu’assez pour cette épreuve. Vous pouvez également télécharger et installer ElasticSearch sur votre appareil ou utiliser un serveur dédié. Si vous ne voulez pas l’installer, vous pouvez télécharger et exécuter la version Docker ( https://hub.docker.com/_/elasticsearch).
Nous avons besoin d’une instance de Kibana. Lorsque vous ouvrez votre compte cloud, cette instance est incluse dans le Stack. Vous pouvez également télécharger et installer Kibana sur votre appareil, ou utiliser la même serveur InfluxDB. Si vous ne voulez pas l’installer, vous pouvez opter pour la version Docker.
De plus, nous avons besoin d’un exemple de Grafana ( https://grafana.com/), après avoir créé un compte sur grafana.com, vous pouvez générer une instance Grafana Cloud ici. Cette instance serait suffisante pour ce test. Vous pouvez également télécharger et installer Grafana sur votre appareil ou utiliser le même serveur InfluxDB. Si vous ne voulez pas l’installer, vous pouvez opter pour la version Docker.
Ajoutez le Backendlister à un script de JMeter et configure-le avec les informations du point #1.
Vérifiez que l’information est disponible dans Elasticsearch.
- Construisez vos propres tableaux ou utilisez des tableaux existants pour afficher les graphiques de résultats.
Recette #
1.- Version de Elasticsearch et Kibana pour les tests #
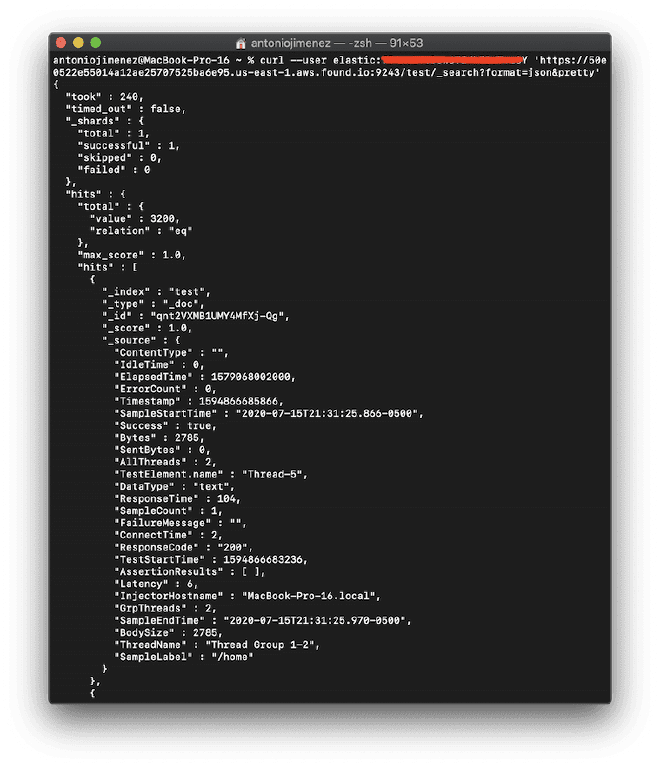
Nous utiliserons la version test d’Elasticsearch, comme vous pouvez le voir dans les images. Par conséquent, obtenir une URL où notre API service https://50e0522e55014a12ae25707525ba6e95.us-east-1.aws.found.io:9243.
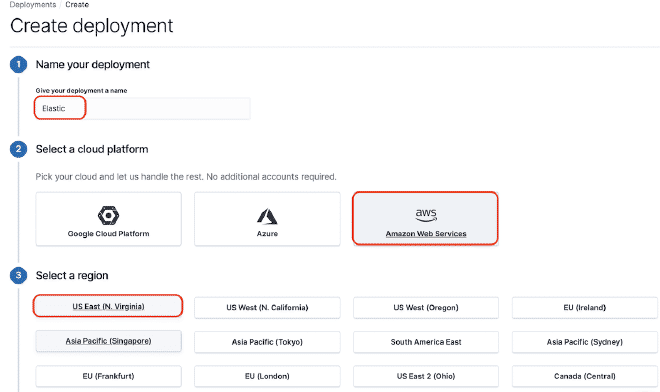
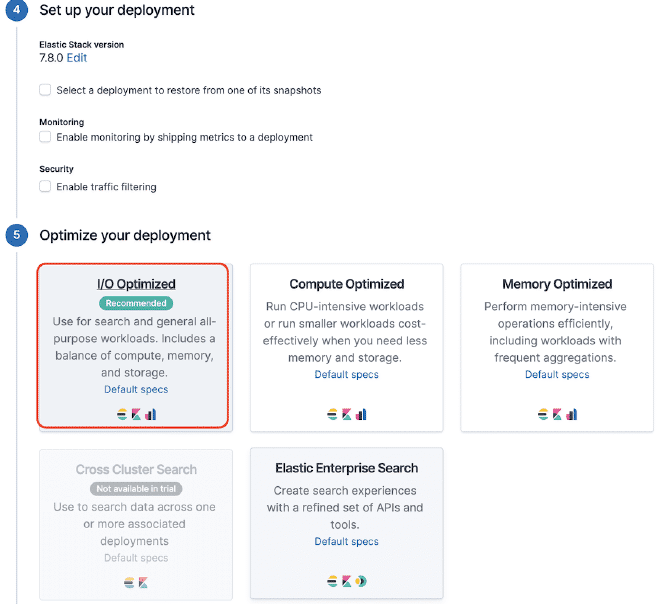

Cliquez sur le rectangle rouge pour obtenir la liane ElasticSearch. Pour cet exemple, elle est https://50e0522e55014a12ae25707525ba6e95.us-east-1.aws.found.io:9243
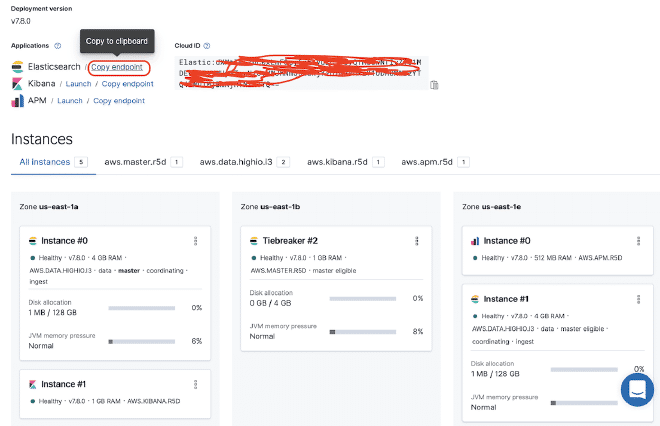
2.- Configurer le Receveur Back-end #
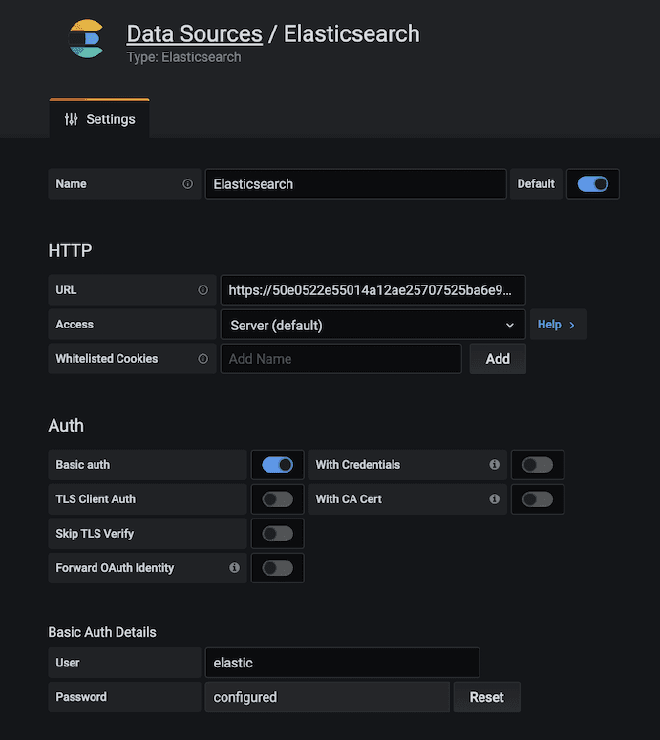
Nous devons copier le fichier jmeter.backendlistener.elasticsearch-2.7.0.jar dans notre répertoire /lib/ext et relancer JMeter. Ensuite, ajouter et configurer le composant Backend listener avec les données de la étape #1 comme nous l’avons déjà mentionné : l’URL est Elastic, et les identifiants de connexion sont obtenus des images précédentes.
- le protocole ou es.scheme = https
- le nom de la serveur ou es.host = 50e0522e55014a12ae25707525ba6e95.us-east-1.aws.found.io
- le port ou es.port = 9243
- l’index ou es.index = jmeter_metrics
- le user d’Elastic ou es.xpack.user = elastic
- la password du user ou es.xpack.password = secret
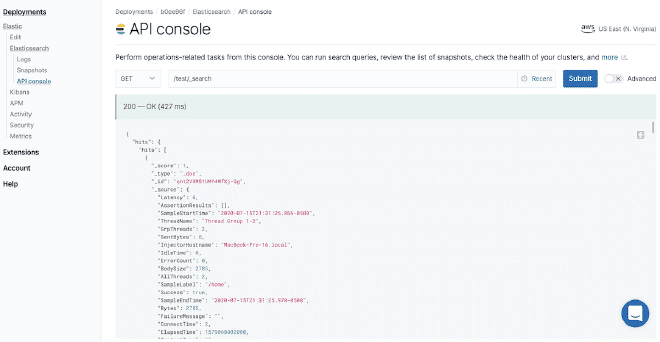
curl --user elastic:secret 'https://50e0522e55014a12ae25707525ba6e95.us-east-1.aws.found.io:9243/test/_search?format=json&pretty'
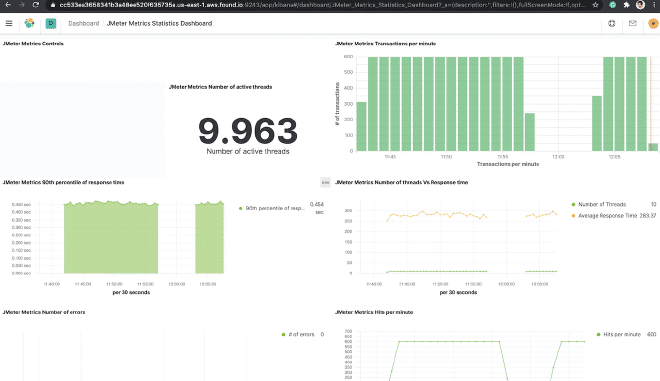
4.- Construire le dashboard #
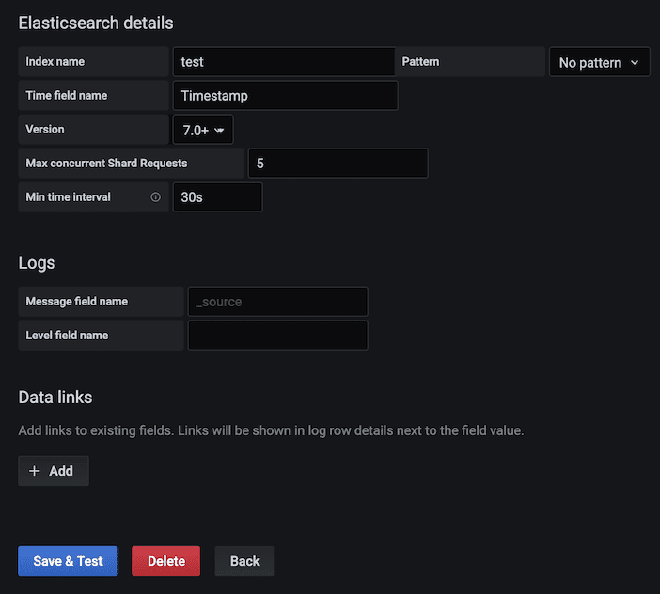
Vous pouvez construire un dashboard dans Kibana pour pouvoir grapher les données qui ont été envoyées à Elasticsearch. Pour cet exemple, nous utiliserons le dashboard JMeter Metrics Statistics Dashboard, qui nécessite simplement de copier le JSON et d’importer-le dans les Objets Kibana. Cependant, avant cela, nous devons configurer l’index de données pour que Kibana puisse extraire-les de Elasticsearch.

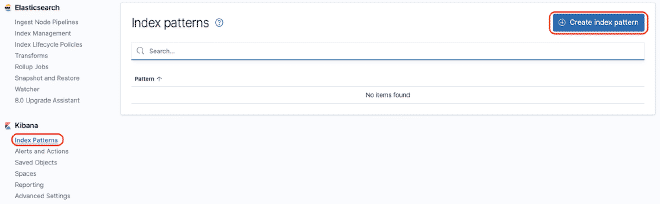
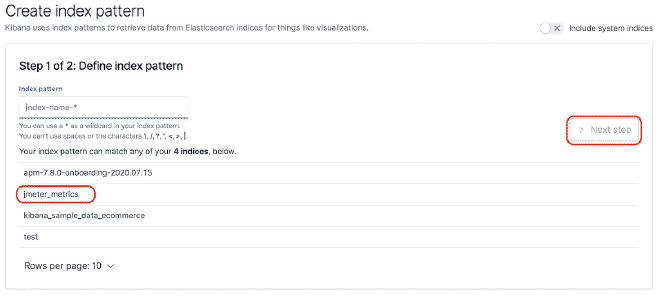
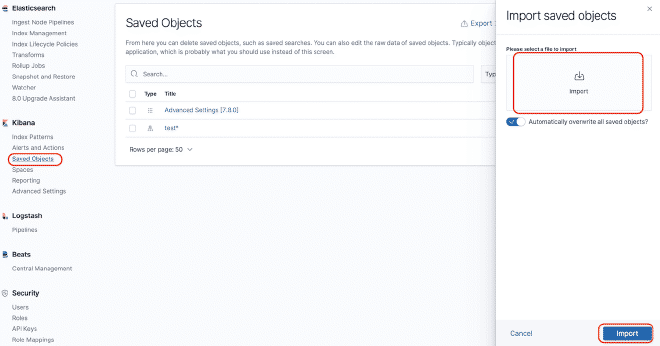
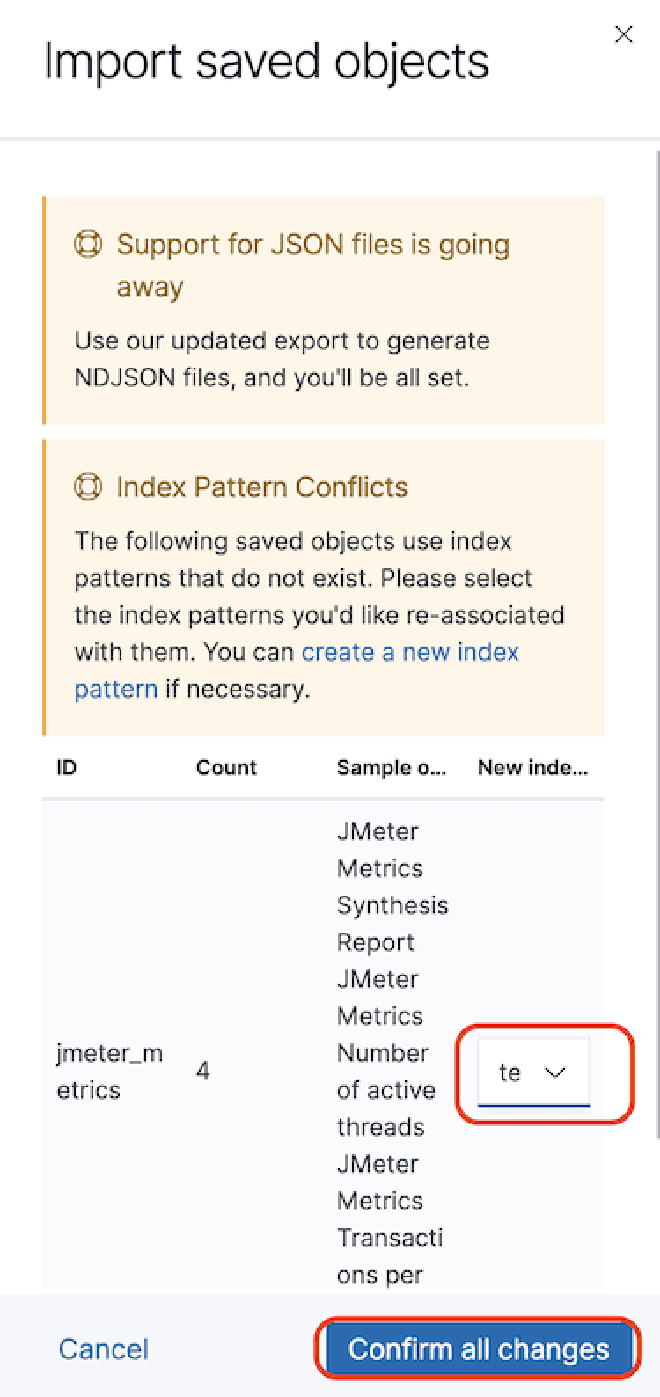

Dans le cas de problèmes de timestamp, nous devons modifier la “détail du dashboard” puis la “visualisation” du composant. Sélectionnez la “Option Panel” et dans le champ “Field Time,” sélectionnez la valeur “SampleStartTime.” Sauvegardez et profitez du Dashboard.
5.- Alternating using Grafana #
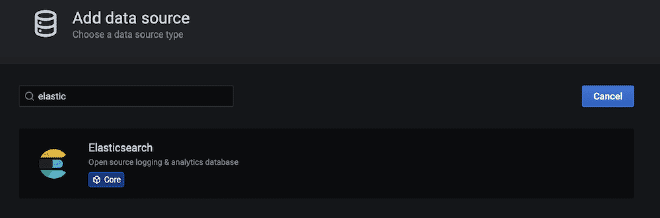
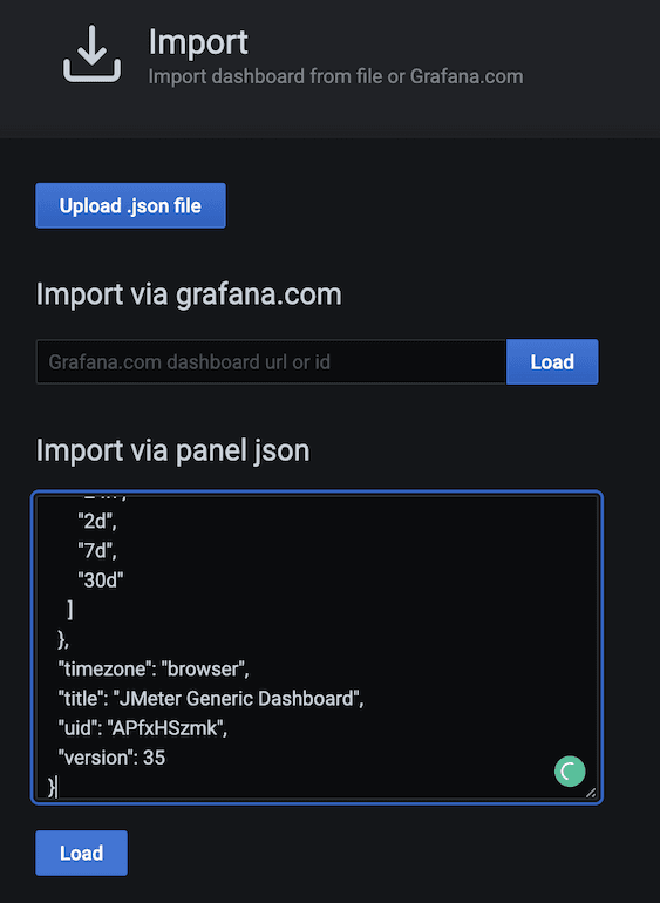
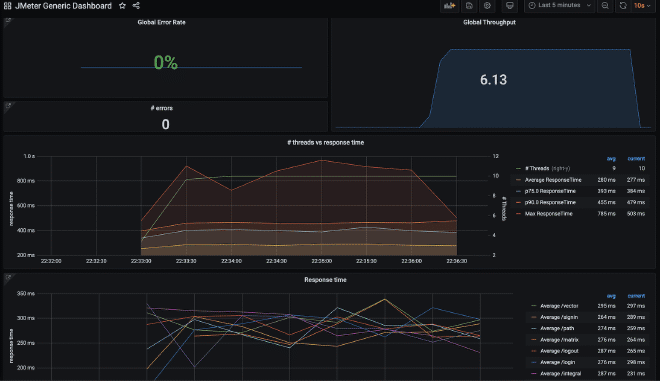
Vous pouvez construire un compte-bouton similaire dans Grafana pour graphique les données qui ont été envoyées à Elasticsearch, la meilleure façon est de utiliser des comptes-boutons pré-creés par certains utilisateurs du communauté Grafana, ces sont disponibles à l’adresse suivante lien. Pour cet exemple nous allons utiliser le compte-bouton Compte-bouton principal de Grafana, qui nécessite seulement que nous copions et importons le JSON dans Grafana. Cependant, avant cela, nous avons également besoin d’configurer la connexion de source entre Grafana et Elasticsearch.

Conclusion #
Cette solution a également fonctionné pour des milliers de utilisateurs concurrents, car elle est très simple à élargir horizontalement Elasticsearch. Bien que Kibana ou Grafana avec les instances cloud soient suffisants, je propose aux personnes qui deviennent plus expérimentées d’élaborer leurs propres tables dans Kibana ou Grafana ou de modifier les tables existantes, ce qui est très facile et extrêmement utile. Parce que vous pouvez également envoyer des comptes pour CPU, mémoire, espace disque et bande passante des générateurs de charge ou des serveurs cibles en utilisant Logstash.
Alternativement, nous pourrions envoyer le contenu de notre fichier JTL via Logstash, ce qui pourrait éliminer la nécessité de collecter les fichiers JTL après des itérations si nécessaire, bien que cette Listener soit différente du précédent article sur InfluxDB, permettant d’enregistrer tous les champs et résultats sans avoir besoin de stocker le fichier JTL pour la reconstruction si nécessaire.
De même que de déposer les métriques des comptages vers Elasticsearch, nous pourrions corriger les niveaux de charge avec les comptages du CPU, de la mémoire et de l’I/O pour mesurer le rendement des serveurs cibles. Par conséquent, bien qu’EJMeter soit un outil de test de chargeur, il peut facilement être intégré à ces add-ons pour mesurer le rendement.
Pour finaliser, si vous souhaitez comparer vos résultats dans un environnement CI/CD, Anthony Gauthier nous a laissé une surprise ici. Bonne chance !