Exécution Distribuée de JMeter (AWS Fargate + Docker)
Sommaire
avancé - This article is part of a series.

À ce terme de notre série distribuée sur JMeter, nous utilisons cette fois-ci les conteneurs. Il existe une grande variété de modèles possibles car nous pouvons utiliser un grand nombre de plateformes basées sur des conteneurs pour l’administration et la gestion orchestrée_ Kubernetes, comme :
- Amazon Elastic Kubernetes Service (EKS)
- Azure Kubernetes Service (AKS)
- Google Kubernetes Engine (GKE)
- Rancher, etc.
Nous pouvons également utiliser des versions non-Kubernetes :
- Amazon ECS (Elastic Container Service) à AWS.amazon.com/ecs/
- Azure Container Instances (ACI) à Azure.microsoft.com/services/container-instances/
- Google Cloud Run à Google.cloud.run/ etc.
Pour cet exemple particulier, nous utiliserons la solution Amazon ECS (Elastic Container Service) avec le service Fargate.
Quand il serait judicieux d’entreprendre l’effort ? #
Comme j’ai indiqué dans mes publications précédentes JMeter distribué localement et JMeter distribué publiquement, je vous conseille d’utiliser cette approche si vous devez effectuer un test de charge ou de stress entre 8.000 et 25.000 threads ou utilisateurs virtuels. Cela est due à l’investissement de temps et d’énergie nécessaire pour le permettre. Bien sûr, ce mode peut être étendu bien au-delà de 25k threads. Cependant, je recommande d’utiliser EC2 plutôt que Fargate et de demander une assistance en matière de surveillance des instances et résultats dans le temps réel.
Comment ça marche ? #
Cette architecture ne fonctionne plus en mode master-slave. Le principal motif est que la mécanique de communication entre le maître et les esclaves, RMI (Java Remote Method Invocation), n’est pas très efficace pour des volumes importants et pourrait générer des bouchons (ironique). Chaque conteneur en cours sera un générateur de charge, et pour créer l’image du conteneur, nous baserons sur le flux alternant de la guide JMeter + Docker.
Une fois que l’image est disponible dans le répertoire AWS, nous pouvons définir une tâche liée à cette image. Pour exécuter-la, elle sera réalisée via Fargate et nous pourrons atteindre un maximum de 50 tâches. N’oubliez pas que chaque tâche serait soit un conteneur actif ou un générateur de charge, ce qui donne accès à 50 générateurs de charge disponibles.
Après l’exécution, les fichiers de résultats JTL et le journal de JMeter seront copiés vers S3 afin que vous puissiez les télécharger, les traiter ou archiver comme preuve de l’exécution. Voici un exemple similaire à ce qui nous est proposé suivant mais il est effectué via le ligne de commande et est en anglais.
Recette pour cuire
Clonez l’archive suivante pour obtenir les fichiers nécessaires pour construire notre image Docker :
clone git https://github.com/daeep/JMeter_Docker_AWS.git
cd JMeter_Docker_AWS
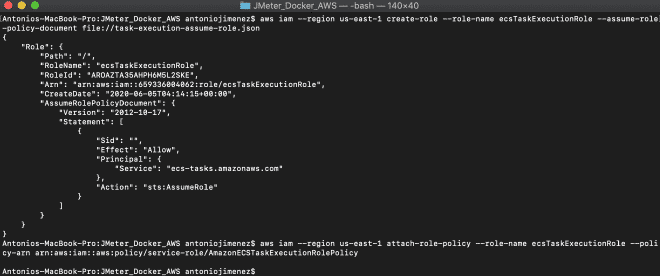
2. Générer le rôle IAM #
Nous générnerons une certaine rôle pour exécuter des tâches dans Fargate, cette rôle est appelée ecsTaskExecutionRole. Cette rôle peut être générée via la ligne de commande ou par l’interface AWS Management Console. Je recommande d’installer et de configurer le CLI AWS CLI pour créer cette rôle en utilisant le fichier task-execution-assume-role.json inclus dans le répertoire que nous avons téléchargé.
aws iam --region us-east-1 create-role --role-name ecsTaskExecutionRole --assume-role-policy-document file://task-execution-assume-role.json
aws iam --region us-east-1 attach-role-policy --role-name ecsTaskExecutionRole --policy-arn arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy
Comme vous pouvez le voir, je travaille dans la région us-east-1.
3. Ajoutez le conteneur S3 et les identifiants d’AWS à votre fichier Docker #
Nous devons modifier et adapter notre Dockerfile situé dans la racine JMeter_Docker_AWS, qui est partie de ce projet. Ce projet envisage de sauvegarder les fichiers de résultats dans S3, bien que nous puissions aussi sauvegarder les résultats dans InfluxDB ou ElastiSearch pour être consommés par Grafana ou Kibana, respectivement. Pour sauvegarder les fichiers de résultats dans S3, nous devons créer un bucket et inclure nos identifiants d’AWS sur les lignes 18-20 du Dockerfile, ces identifiants pourraient être les mêmes que ceux utilisés par l’outil AWS CLI si vous lui avez accordé des autorisations administratrices.
18 ENV AWS_ACCESS_KEY_ID #####################
19 ENV AWS_SECRET_ACCESS_KEY #################
20 ENV AWS_DEFAULT_REGION #################### <-- can be the region (us-east-1)
Finalement, nous devons modifier les lignes 53 et 54 avec le nom du bucket où seront stockés les fichiers. Voici un guide en espagnol ici pour créer des buckets. Si vous ne voulez pas sauvegarder le fichier JTL et la bitstream de log JMeter, vous devrez supprimer les lignes 18-20 et 49-54. Cependant, je ne recommande pas ce que faire.
53 && aws s3 cp ${JMETER_HOME}/result-${PUBLIC_IP}-${LOCAL_IP}.jtl s3://nombre-del-bucket/ \
54 && aws s3 cp ${JMETER_HOME}/jmeter-${PUBLIC_IP}-${LOCAL_IP}.log s3://nombre-del-bucket/
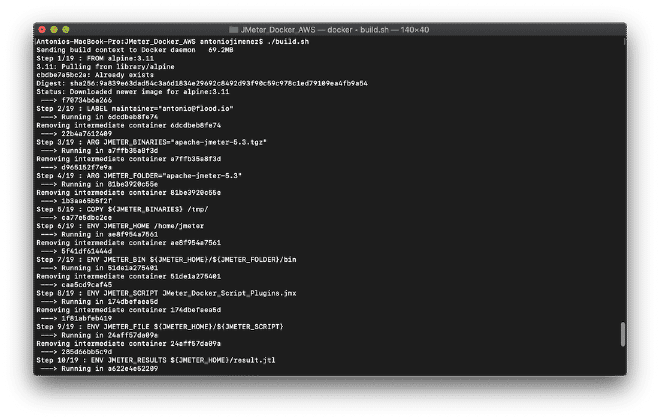
Construire le fichier Docker #
Nous compilons notre image avant de l’envoyer vers la répertoire. Nous pouvons le faire en exécutant le script shell ./build.sh situé dans notre dossier ou par la commande: docker build -t jmeter-docker ., qui est très similaire à la publication du projet JMeter + Docker. Ce projet est également préparé pour compiler l’image avec nos binaires locaux, mais maintenant il copiera le script JMX dans le conteneur (modifiez la ligne 13). Si vous avez besoin de support files comme CSV ou images, ajoutez-les de manière similaire à les lignes 11, 13, 14 et 17.
11 ENV JMETER_HOME /home/jmeter <-- Carpeta local interna
...
13 ENV JMETER_SCRIPT JMeter_Docker_Script_Plugins.jmx <-- Nombre de tu script local
14 ENV JMETER_FILE ${JMETER_HOME}/${JMETER_SCRIPT} <-- Archivo final interno
...
17 COPY ${JMETER_SCRIPT} ${JMETER_FILE} <-- Copia el archivo local dentro del contenedor
5.- (Optionnel) Si vous avez besoin d’une plus grande mémoire #
Une fois que notre image est compilée, nous pouvons la lancer localement pour valider qu’elle fonctionne bien. Pour cela, vous pouvez alterner les lignes 21 ou 22, qui contiennent des valeurs différentes pour JVM_ARGS. Il faut noter que ce script est paramétré suivant les instructions décrites paramètres. Remarquez qu’il convient de récompilé avant d’exécuter si vous avez modifié cette valeur et enfin pour lancer, nous pouvons utiliser le script shell ./run.sh.
21 ENV JVM_ARGS="-Xms2048m -Xmx4096m -XX:NewSize=1024m -XX:MaxNewSize=2048m -Duser.timezone=UTC" <-- Suficiente para algunos cientos de usuarios concurrentes
22 ENV JVM_ARGS "-Xms256m -Xmx1024m -XX:NewSize=256m -XX:MaxNewSize=1024m -Duser.timezone=UTC" <-- Suficiente para algunas decenas de usuarios concurrentes
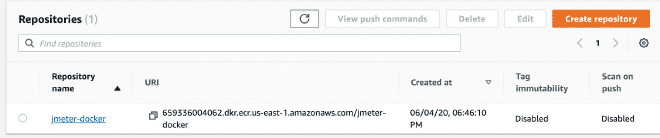
6.- Créer le répertoire ECS et envoyer l’image Docker #
Nous poursuivons en créant un compte AWS ECS, c’est pas compliqué. Vous pouvez également consulter les étapes ici une fois que vous avez le compte prêt. Nous envoyerons l’image avec les commandes suivantes :
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin 659336004062.dkr.ecr.us-east-1.amazonaws.com
docker tag jmeter-docker:latest 659336004062.dkr.ecr.us-east-1.amazonaws.com/jmeter-docker:latest
docker push 659336004062.dkr.ecr.us-east-1.amazonaws.com/jmeter-docker:latest
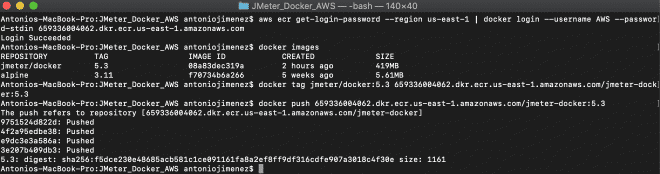
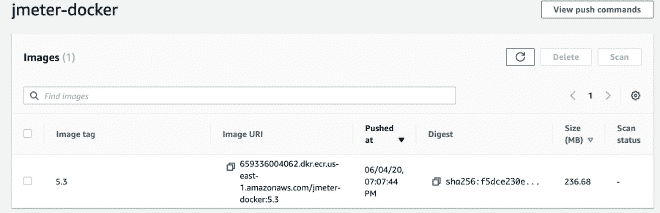
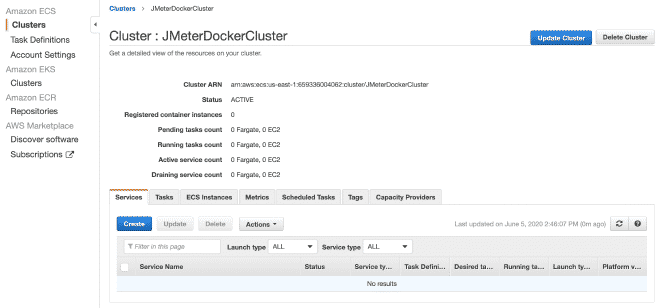
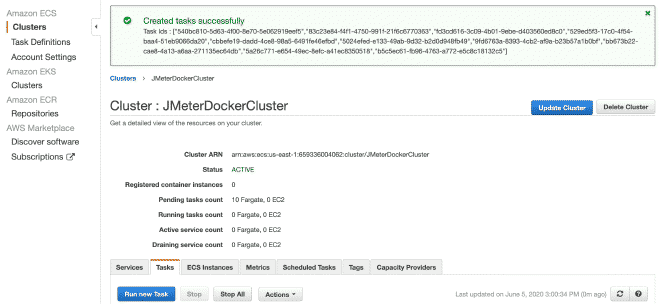
Créez un cluster Fargate #
Maintenant nous créerons un cluster Fargate. Je pense que vous pouvez reproduire les étapes en suivant les images.

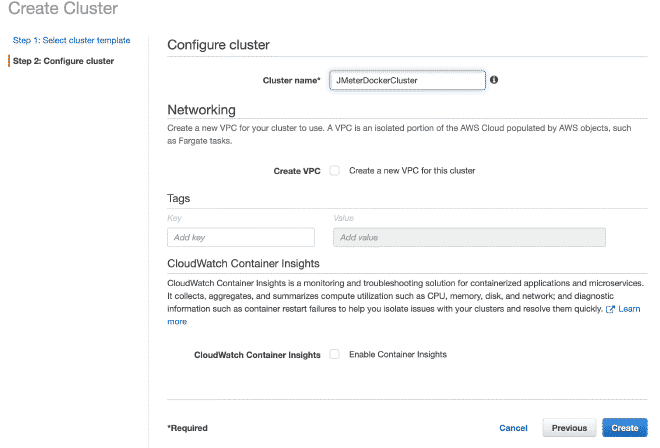

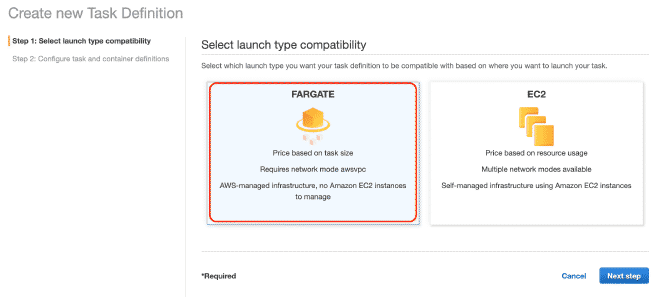
Définir les Tâches dans Fargate #
Nous définirons une nouvelle tâche, et je pense que c’est possible de continuer uniquement avec des images.

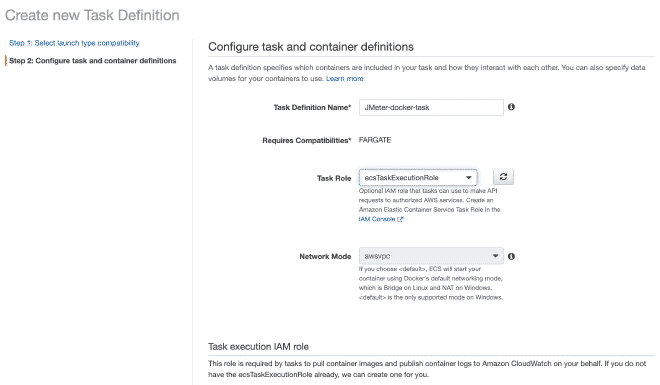
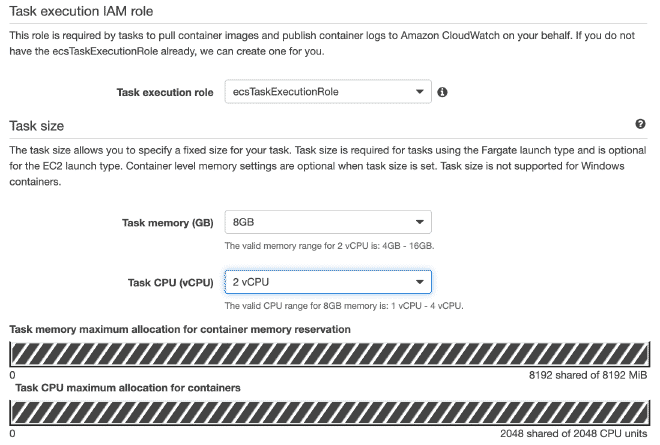
Rappelez-vous que les valeurs pour le CPU et la mémoire, ainsi que le seuil de mémoire doux sont configurables et je recommande d’initialiser avec quelques threads afin de ne pas rapidement épuiser les ressources et échouer au test.
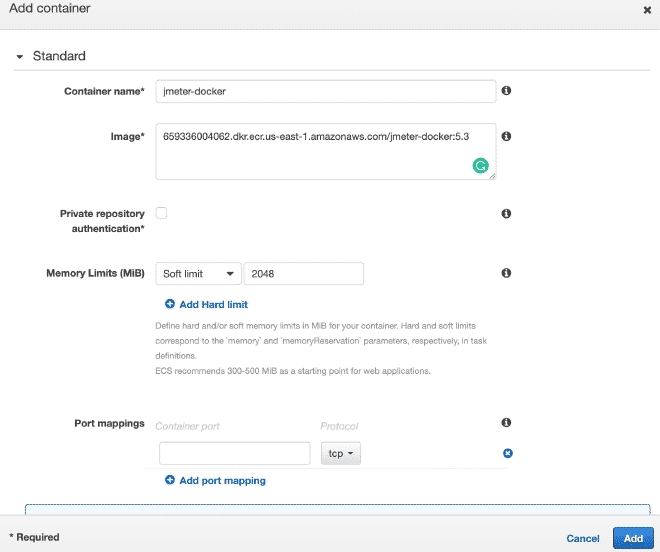
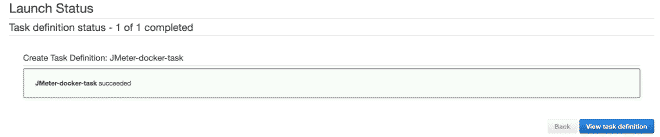
Exécuter les Tâches #
Enfin, nous exécuterons les(tes) tâche(s) dans notre Cluster. Le maximum de tâches par cluster est de 10. Si nous voulons exécuter plus de tâches, nous devrons générer d’autres clusters. La réduction du temps d’exécution sera très grande car le job a déjà été défini et il sera facile de l’exécuter dans plusieurs clusters. Je comprends que la limite totale de 50 tâches signifie 5 clusters en exécutant jusqu’à 10 tâches maximum, mais aussi vous pouvez demander des augmentations des limites, bien qu’il soit recommandé d’utiliser EC2 plutôt que Fargate si nous avons besoin de plus de puissance informatique.
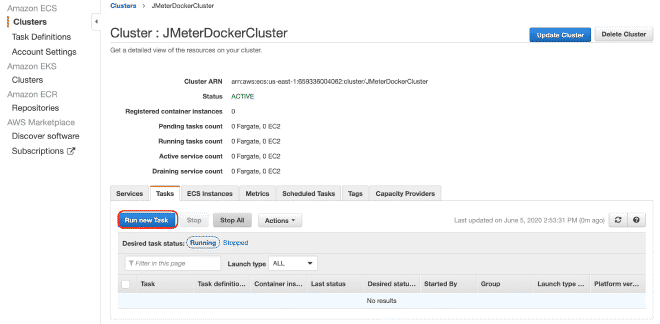
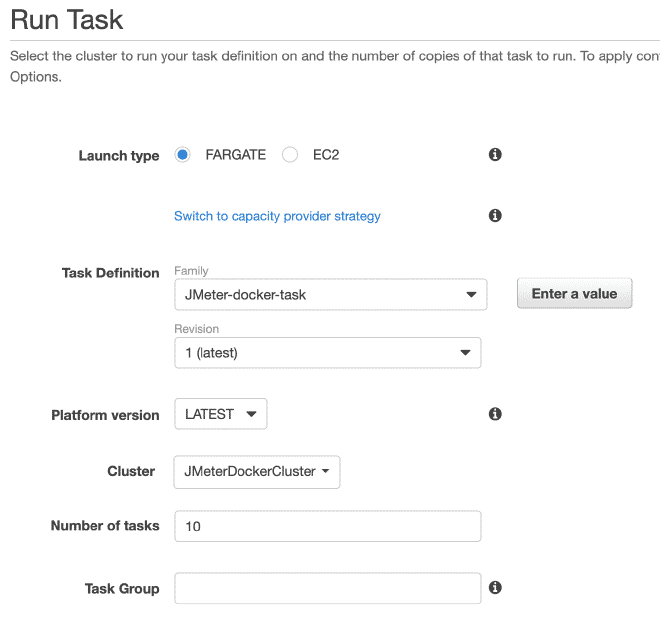
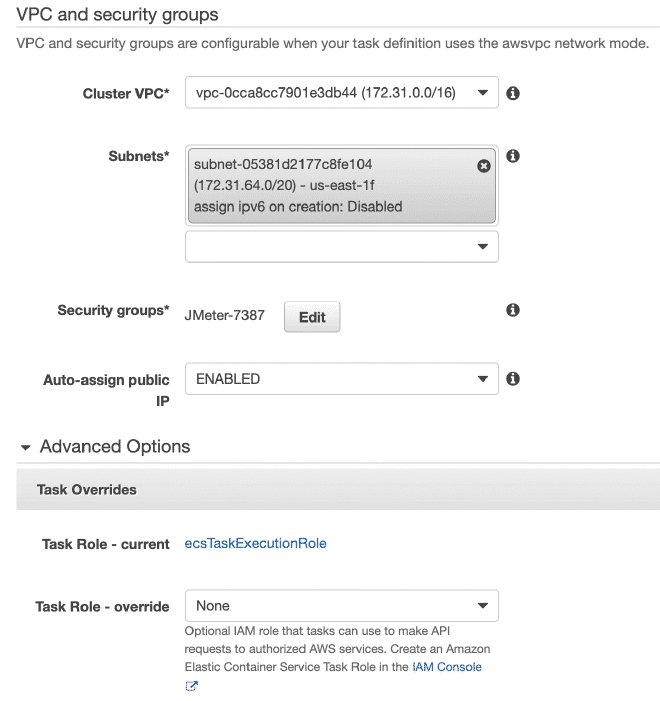
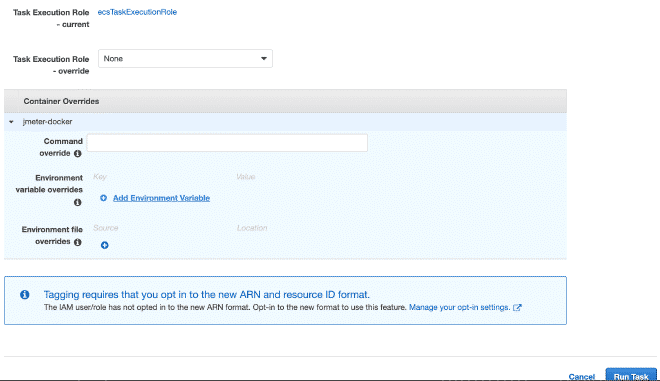
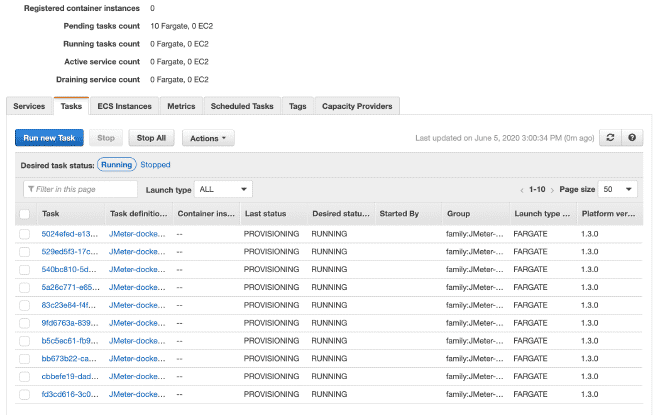
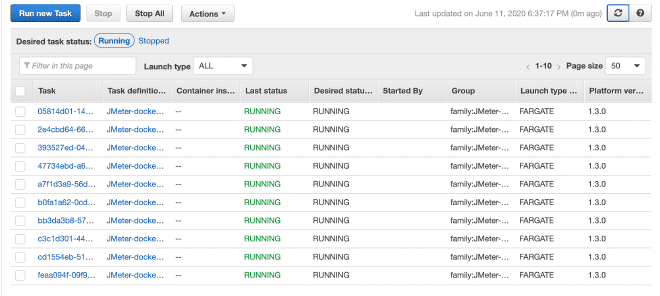
Dans la section exécution du travail, nous pouvons définir des variables d’environnement. Par conséquent, si nous voulons effacer ou annuler n’importe quel variable comme les utilisateurs, le déclenchement ou la durée, nous pouvons l’effectuer ici.
Concluison #
Je comprends que beaucoup de pas et ils pourraient sembler difficiles, surtout si vous êtes nouveau sur AWS ou ECS. Cela dit, j’ai décidé d’annoncer la section Docker avant de décrire l’AWS section, espérant que ma tentative de simplifier le contenu aidera à reproduire ce qui a été écrit. Cette solution est extrêmement flexible et pourrait être utilisée avec n’importe quel autre orchestration des conteneurs pour exécution et obtenir les mêmes résultats similaires. Il faut également noter que nous avons réussi à résoudre certaines sections via docker compose ou ec2_param dans le format YAML par commande ligne de commandes, mais l’intention était simplement d’aider à simplifier le contenu. J’espère qu’ils peuvent reproduire ce schéma sans hésitation en contactant nous si nécessaire.
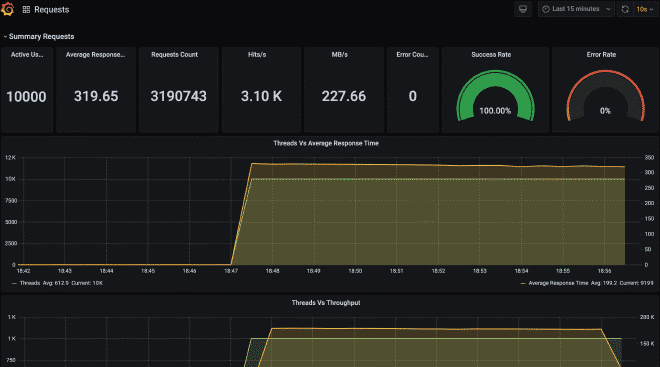
Enfin, je vous laisse avec comment les fichiers auraient l’air dans S3 et le graphique de Grafana avec les informations provenant de cette exécution.
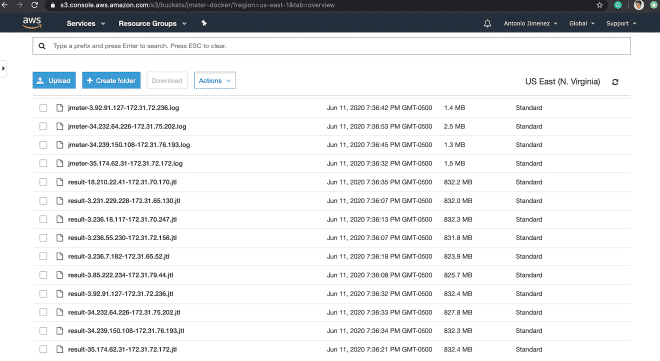
https://jmeter-docker.s3.amazonaws.com/result-35.174.62.31-172.31.72.172.jtl