

JMeter (InfluxDB + Grafana)
Sommaire
avancé - This article is part of a series.

Qu’est-ce que l’InfluxDB ? #
InfluxDB est un service de base de données temporelle en temps réel, idéal pour stocker des résultats numériques ou des résultats en temps réel. La réussite d’InfluxDB repose sur son implémentation en Go, qui la rend plus performante que les autres bases de données temporaires en temps réel (bases de données temporelles). Nous pourrions mettre en œuvre le solution présentée dans cet article avec Graphite, mais je pense qu’il serait recommandé si vous deviez comparer les résultats ou effectuer des “benchmarking”.**
L’administration, la lecture et l’enregistrement des données dans InfluxDB peuvent être effectués via son API de service, qui reçoit les requêtes sur le protocole HTTP et exécute les opérations en langage InfluxQL (similaire à SQL) sur notre base de données. L’injection peut être unitaire ou batchée, ce qui signifie qu’elle peut envoyer une requête HTTP avec un ou plusieurs mesures simultanément. De plus, l’ingestion en gros lot ou en format CSV brut pourrait être réalisée, mais cela ne se trouve pas dans notre champ d’action. Je recommande de visiter cet article pour essayer InfluxDB. Enfin, mais non moins important, InfluxDB est un projet open-source.
Qu’est-ce que Grafana ? #
Grafana est un outil pour visualiser des tableaux de bord et des graphiques qui sont alimentés par les données mesurées provenant d’entreposages temps-série. Cela se limite à une période implicite ou fenêtre, ce qui signifie que seul le tableau de bord peut être scellé dans un intervalle de temps spécifique. De même, Grafana et InfluxDB sont des projets écrits en GoLanguage également comme des projets open source.
Ce outil nous aide à comprendre et/ou analyser les comportements ou les patterns en utilisant la simplicité pour modifier les fenêtres de temps, recalculer les valeurs sur une nouvelle fenêtre après les modifications. Nous pouvons facilement voir le comportement historique du CPU ou de la mémoire d’un ou plusieurs serveurs par jour, semaine, mois ou année. Avec cette information, nous pouvons comprendre nos habitudes actuelles de consommation et prévoir nos comportements futurs.
Comment fonctionne l’intégration de InfluxDB et de Grafana avec JMeter ? #
La intégration est assez simple et populaire, donc si bien que le JMeter possède une composante natif appelée Listener Backend. Ce listener reçoit les requêtes de JMeter via des appels HTTP asynchrônes à InfluxDB. Les résultats obtenus par JMeter grâce aux blocs peuvent être stockés dans InfluxDB, ce qui peut ensuite être lu ou graphifié sur une carte Grafana pour la visualisation.
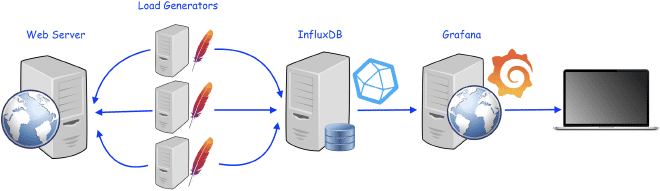
Le récepteur enverra tous les résultats décrits ici à l’InfluxDB, soit placé au niveau de la liste d’enregistrement backend du plan de test, soit dans une spécifique groupe de thread. Les résultats seront envoyés à l’InfluxDB en un maximum de 5000 lignes, chaque ligne peut contenir plusieurs mesures. Par ailleurs, cela ne signifierait pas beaucoup pour l’InfluxDB. La données est transmise via des requêtes HTTP POST au API InfluxDB, il serait bon d’avoir une seule personne pour écrire et une autre pour lire (pour la sécurité). Une fois que vous aurez validé que les données sont entrées correctement, nous pouvons construire un dashboard dans Grafana pour afficher les résultats de votre test JMeter. N’inquiétez pas si vous ne savez pas comment le faire ; il y a beaucoup de dashboards prédéfinis disponibles sur la communauté Grafana pour visualiser les résultats de votre test JMeter.
Qu’est-ce qu’on demande ? #
Nous avons besoin d’un serveur de base de données dans InfluxDB. InfluxData fournit une période de test de 15 jours avec un instance de jusqu’à 4 vCPUs et 16 Go de RAM, ce qui est suffisant pour cette épreuve. Vous pouvez également télécharger et installer InfluxDB sur votre ordinateur ou utiliser une serveur dédié. Si vous ne voulez pas l’installer, vous pouvez télécharger et exécuter la version Docker de InfluxDB.
Nous avons besoin d’une instance de Grafana. Lorsque vous ouvrez votre compte à grafana.com, vous pouvez générer une instance Grafana Cloud. Cette instance serait suffisante pour ce test. Vous pouvez également télécharger et installer Grafana sur votre ordinateur, ou utiliser le même serveur InfluxDB. Si vous ne voulez pas l’installer, vous pouvez opter pour la version Docker.
Créer une base de données dans InfluxDB et créer un utilisateur pour la lecture et l’écriture (le même utilisateur peut être utilisé pour les deux tâches).
Ajoutez un écouteur de backend à votre script JMeter et configure-le avec les informations du pas #1.
Vérifiez que l’information est disponible dans InfluxDB.
- Construisez vos propres tableaux de bord ou utilisez des graphiques existants pour afficher les résultats.
Recette de cuisine #
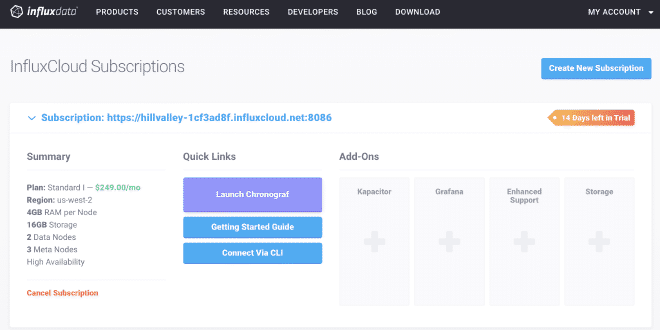
1.- Version InfluxDB et création de base de données #
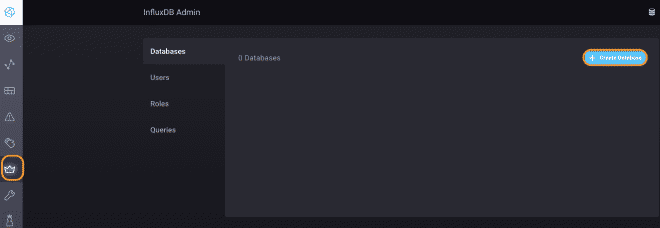
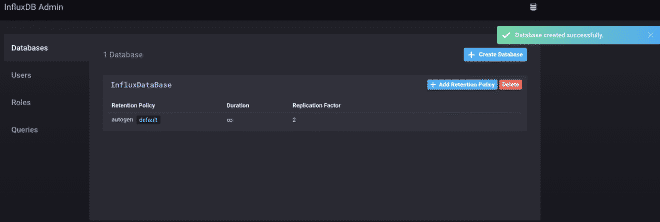
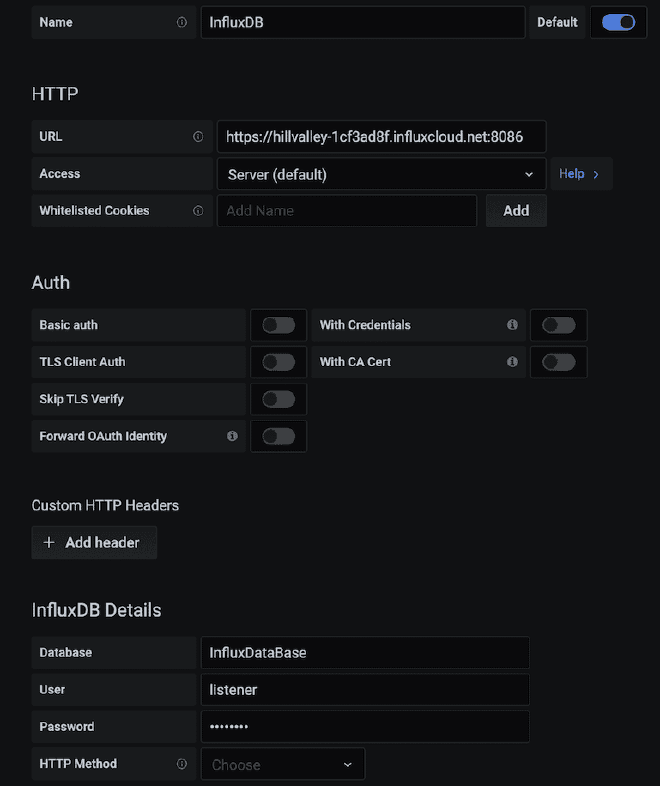
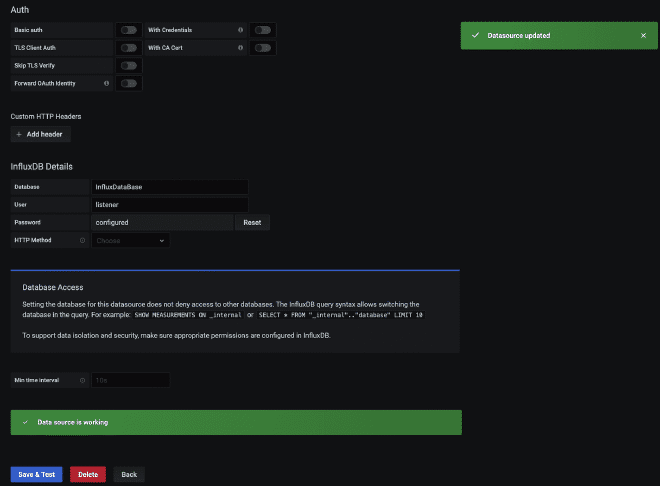
Nous utiliserons la version test d’InfluxDB, comme vous pouvez le voir dans les images. Nous obtenons une URL où se trouve notre service API https://hillvalley-1cf3ad8f.influxcloud.net:8086. Lors de l’initialisation de Chronograf, nous sélectionnons l’option pour administrer InfluxDB afin de générer notre base de données, appelée InfluxDataBase. Nous créons également le utilisateur listener et sa clé de secret. Pour faciliter la interaction avec ce user, il peut lire et écrire des données, à usage de JMeter et Grafana.
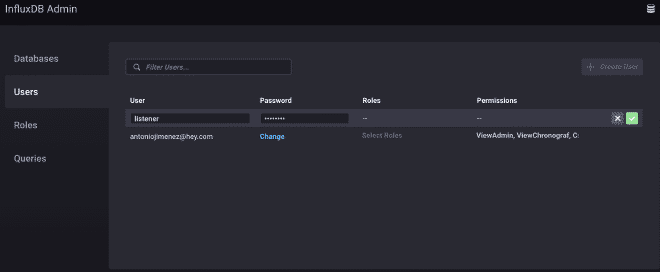
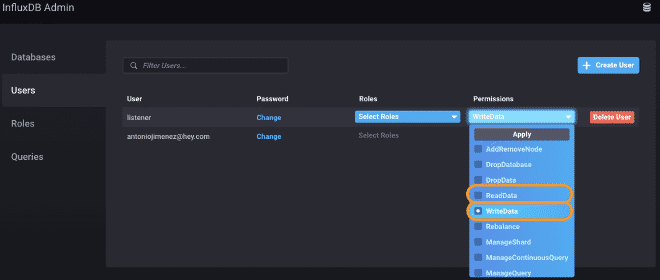
2.- Configurer le Receveur Back-End #
Nous devons ajouter et configurer le écouteur de la réception avec les données provenant du point #1, comme nous l’avons déjà mentionné que l’URL est https://hillvalley-1cf3ad8f.influxcloud.net:8086, mais aussi nous devons spécifier la base de données à laquelle on veut écrire les résultats et également authentifier le utilisateur et mot de passe avec lequel on interagira. C’est facile, ces valeurs peuvent être envoyées en tant que paramètres dans l’URL suivante : https://hillvalley-1cf3ad8f.influxcloud.net:8086/write?db=InfluxDataBase&u=listener&p=password, où db est la base de données InfluxDataBase, u est l’utilisateur listener et p est le mot de passe password. Après avoir configuré cela, nous ferons une petite épreuve avec quelques utilisateurs concurrents.
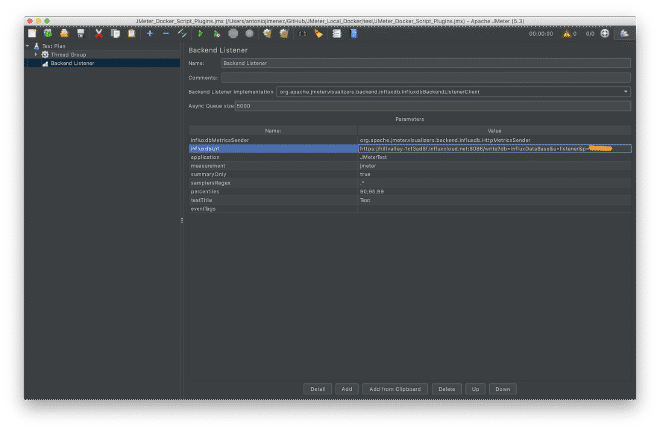
3.- Vérifiez les connexions API DB #
1.- curl -G ‘ https://hillvalley-1cf3ad8f.influxcloud.net:8086/query?db=InfluxDataBase&u=listener&p=password&pretty=true' –data-urlencode “q=SHOW MEASUREMENTS”
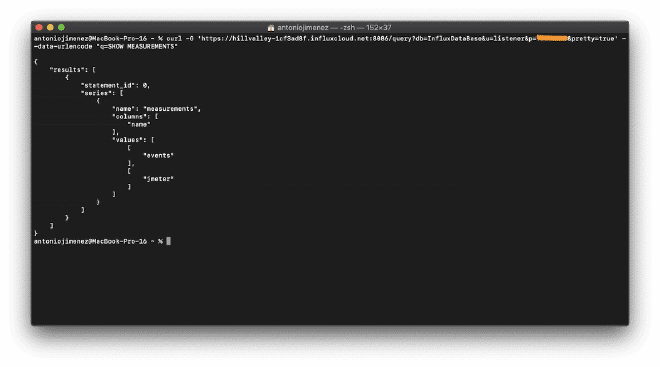
2.- curl -G ‘ https://hillvalley-1cf3ad8f.influxcloud.net:8086/query?db=InfluxDataBase&u=listener&p=password&pretty=true' –data-urlencode “q=SELECT * from jmeter limit 2”
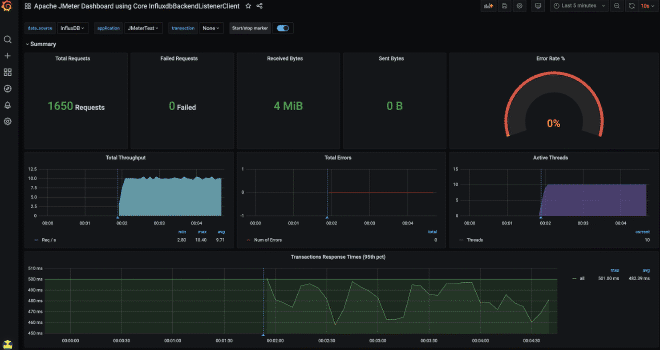
4.- DASHBOARD DE GRAFANA #
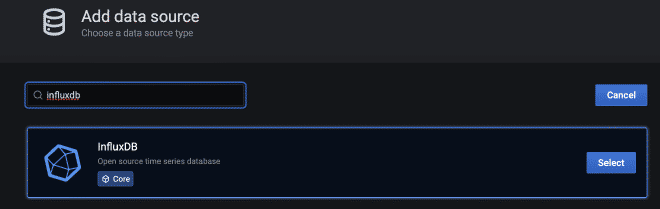
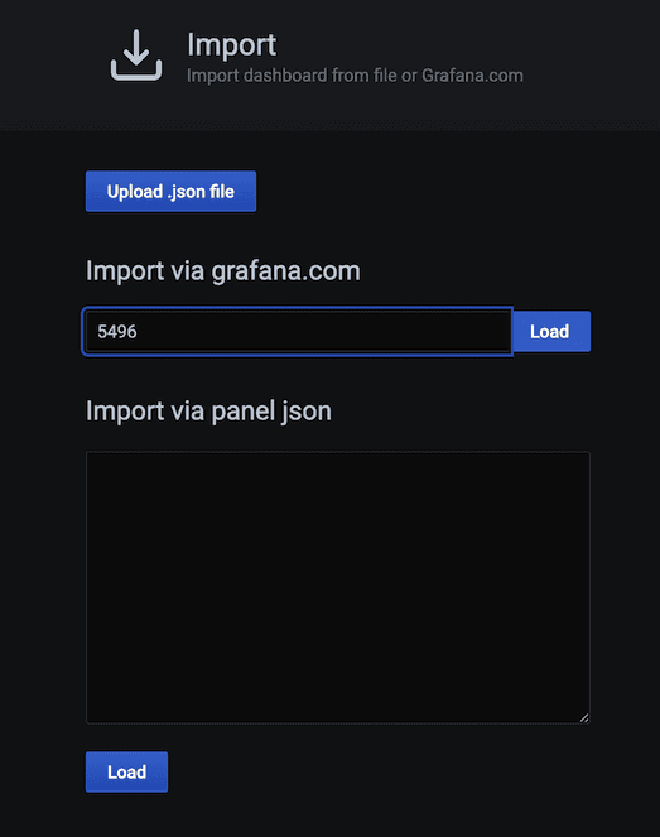
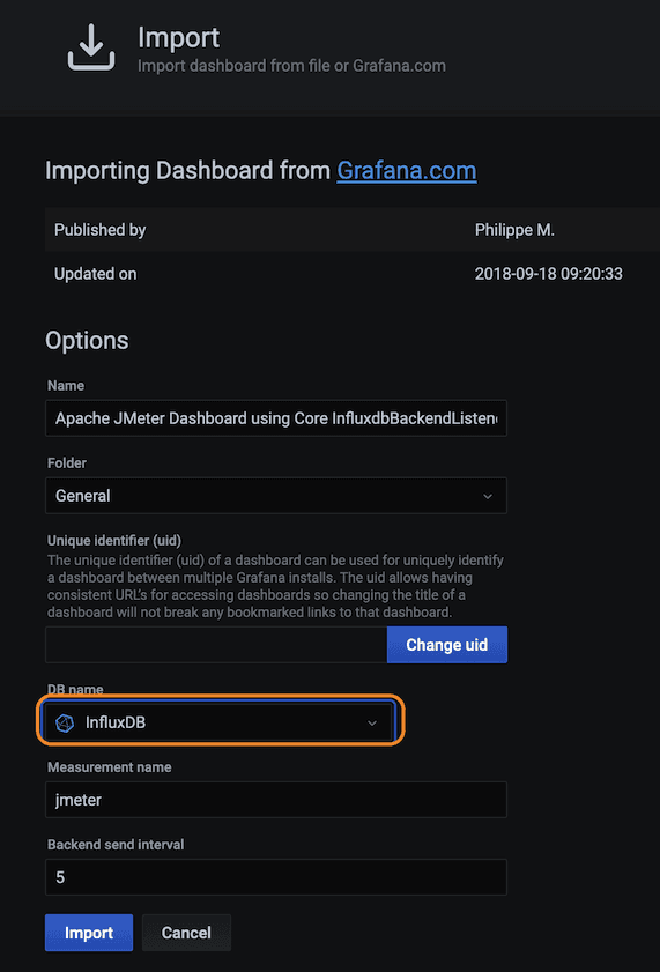
Vous devez construire le dashboard dans Grafana afin de pouvoir graphique les données qui ont été envoyées à l’InfluxDB. La meilleure façon est d’utiliser des dashboards pré-creés par certains utilisateurs du communauté Grafana, disponibles à cette lien. Pour cet exemple, nous utiliserons le dashboard avec le numéro #5496, qui vous pouvez simplement copier et coller dans Grafana. Cependant, avant de configurer la connexion source de données entre Grafana et InfluxDB, vous devez d’abord configurer la connexion.
Conclusion #
Pour cette article, je suis partie de la moitié de mon publication en 2018 et vous pouvez consulter-la ici. La publication est en anglais et utilise deux récepteurs JSR223 avec une langue de programmation Groovy, avec un logiciel très similaire à celui utilisé par le Listener Backend, cependant il y a des différences concernant la forme et les données envoyées vers InfluxDB. De plus, les tables de Grafana ont été spécialement conçues pour cette forme, donc elles ne sont pas compatibles avec cet article. Je n’ai pas couvert ce matériel car ma intention est de fournir une solution simple. Quand vous sentez que vous êtes plus avancé, s’il vous plaît utilisez ou modifiez le code du publication indiquée.
Cette solution a fonctionné pour des milliers de utilisateurs concurrents car elle est très facile à évoluer Horizontalement InfluxDB, tandis que Grafana même avec l’instance en cloud est suffisant. Si ils ont plus d’expérience, je les invite à créer leurs propres tables dans Grafana ou à modifier les tables existantes, c’est assez simple et très utile. Parce qu’elle peut aussi envoyer des comptages de CPU, mémoire, disque et bande passante depuis leurs générateurs de charge ou serveurs cibles en utilisant telegraf ou la solution partagée par Delvis dans cette mesure, avec le but de mesurer et de corriger les niveaux de charge en quantifiant et en correlant les niveaux de consommation, afin que nous puissions mesurer la performance des serveurs impliqués.
Bienvenue dans la surveillance en temps réel de vos résultats et niveaux de consommation. Veuillez noter que cette information est également disponible sur le site officiel du JMeter à l’adresse suivante lien. Bonne chance!