

Extractor de JSON JMESPath
Sommaire
intermédiaire - This article is part of a series.

Qu’est-ce que JMESPath ? #
JMESPath a été développé en 2012 par James Saryerwinnie, ingénieur chez Mozilla Corporation, comme une alternative à la JSONPath pour accéder et manipuler les données dans des documents JSON. Le principal objectif derrière la création de JMESPath était d’élaborer un outil plus efficace et flexible pour accéder aux données dans des documents JSON qui sont largement utilisés dans les applications web et mobiles.
En les années qui suivent, JMESPath s’est popularisé parmi les développeurs travaillant avec des applications web et mobiles utilisant JSON comme format de données d’échange. Il a été intégré dans plusieurs bibliothèques populaires de Python, devenant une outil essentiel pour gérer l’infrastructure en nuage. En 2017, JMESPath s’est transformé en projet open-source sous la direction du projet Python. Depuis lors, il a été adopté par diverses bibliothèques et outils de Python tels que AWS CLI et Terraform, utilisés dans une variété de contextes, allant des analyses de données à la intégration système et au processus automatisé.
Aujourd’hui, JMESPath demeure un outil populaire pour accéder et manipuler les données dans des documents JSON utilisés dans les applications web et mobile. Il est compatible avec une variété de langages de programmation et d’infrastructurees, et est utilisé dans divers contextes tels que la gestion de l’infrastructure en nuage, le traitement du data et la mise en automate des processus.
Qu’est-ce que JSON ? #
JSON (JavaScript Object Notation) est un format de texte léger pour la transmission d’informations entre le client du navigateur et le serveur, ou entre les applications. JSON représente les données sous forme de nœuds et de listes de nœuds, en utilisant une syntaxe claire et facile à lire basée sur les clés { } pour définir les objets et les parenthèses [ ] pour définir les listes.
{
"nombre": "Ana",
"edad": 28,
"direccion": {
"calle": "Calle Principal",
"ciudad": "Ciudad de México",
"estado": "Ciudad de México",
"codigo_postal": "12345"
},
"intereses": ["leer","viajar","cocinar"]
}
| Propriété | Description | Obligatoire |
|---|---|---|
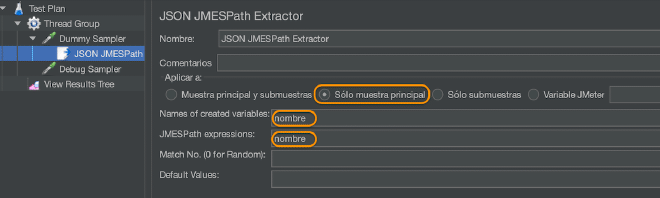
| Nom | Nom décrivant ce élément qui est affiché dans la hiérarchie. | Non |
| Appliquer à | Utile lorsque utilisé avec les mappers qui peuvent générer des sous-samples, tels que le sampler HTTP avec des ressources embedées, Lecteur de Mail ou un contrôleur de transaction générés. Sous-samples uniquement: s’applique uniquement aux sous-samples Sous-samples et principaux: s’applique à tous les deux Principaux et sous-samples: s’applique à tous les deux Nom de variable utilisé dans JMeter: l’extraction sera appliquée au contenu du nom de la variable défini | Oui |
| Nom de Variable Création | Le nom de la variable JMeter où le résultat sera stocké. | Oui |
| Expressions JMESPath | Utiliser la langue JMESPath pour requérir l’élément. 0: sélection aléatoire -1: tous les résultats (par défaut), nommé comme <variable name>_N où N est de 1 à le nombre d’occurrences | Non |
| Nombre Par défaut des Matches (-1 pour aléatoire) | Si la requête JMESPath a beaucoup d’occurrences, vous pouvez choisir lesquelles seront extraitées en tant que variables: 0: sélection aléatoire -1: tous les résultats (par défaut), nommé comme <variable name>_N où N est de 1 à le nombre d’occurrences X: extraire la _X_ème occurrence (où X est plus grand que le nombre d’occurrences, valeur par défaut) | Non |
| Valeur Par défaut | Valeur par défaut retournée lorsque aucune correspondance n’est trouvée. De même retourne si l’élément n’a pas de valeur et option fragment non sélectionnée. | Non |
{
"nombre": "Ana",
"edad": 28,
"direccion": {
"calle": "Calle Principal",
"ciudad": "Ciudad de México",
"estado": "Ciudad de México",
"codigo_postal": "12345"
},
"intereses": ["leer","viajar","cocinar"]
}
nombre //Ana
edad //28
direccion.calle //Calle Principal
direccion.codigo_postal //12345
direccion.ciudad //Ciudad de México
hobbies //["leer","viajar","cocinar"]
What other usage examples might JMESPath have? #
Let’s consider a more complex example, like the following:
[{
"name": "John Doe",
"age": 35,
"address": {
"street": "123 Main St",
"city": "Anytown",
"state": "WA"
},
"phoneNumbers": [
{
"type": "mobile",
"number": "555-551-1234"
},
{
"type": "home",
"number": "555-552-5678"
}
],
"email": "john.doe@example.com"
},{
"name": "Peter Doe",
"age": 34,
"address": {
"street": "123 Second St",
"city": "RacconCity",
"state": "TX"
},
"phoneNumbers": [
{
"type": "mobile",
"number": "555-553-1234"
},
{
"type": "home",
"number": "555-554-5678"
}
],
"email": "peter.doe@example.com"
},{
"name": "Rick Doe",
"age": 36,
"address": {
"street": "123 Third St",
"city": "Springfield",
"state": "NJ"
},
"phoneNumbers": [
{
"type": "mobile",
"number": "555-555-1234"
},
{
"type": "home",
"number": "555-556-5678"
}
],
"email": "rick.doe@example.com"
}]
For this example, suppose we want to evaluate and extract the following data:
| Expression | Result |
|---|---|
| [*].name | returns all the names of the people. |
| [0].phoneNumbers[0].number | returns the mobile phone number of the first phoneNumbers object. |
| [?address.state=='WA'].name | returns the names of people whose state is WA. |
| [*].phoneNumbers[?type=='mobile'].number | returns the mobile phone numbers of the phoneNumbers objects. |
| length([*].phoneNumbers[?type=='home']) | returns the number of phoneNumbers objects of type home. |
| sort_by(@, &age)[0].name | Returns the name of the youngest person. |
| sort_by(@, &age)[-1].name | Returns the name of the oldest person. |
| max_by(@, &age).name | Returns the name of the oldest person. |
| min_by(@, &age).name | Returns the name of the youngest person. |
| [*].name | sort(@) | Returns a list of people’s names in alphabetical order. |
| sum([*].age) | Returns the sum of all ages. |
| length([*].phoneNumbers) | Returns the number of phone numbers. |
| join(', ', [*].phoneNumbers[].number) | Returns a string containing a list of all phone numbers. |
| [?age >= `35` ] | Returns the names of people whose age is greater than 35. |
| [?age >= `35`] | [?address.state == ‘WA’].name | Returns the names of people over the age of 35 who live in WA. |
| [?contains(email,'john')].email | [0] | Returns the email address of the person whose name contains john. |
| [?contains(name, 'Doe')].phoneNumbers[].number | [1] | Returns the second phone number of people whose name contains Doe. |
| [?address.state=='TX'].address.city | sort(@) | [0] | Returns the name of the smallest city in Texas. |
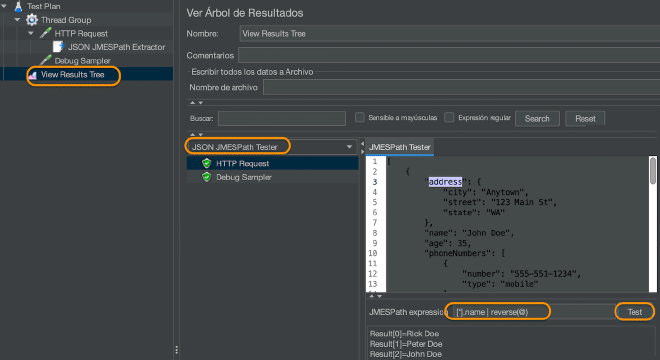
| [*].name | reverse(@) | Returns the names of people from oldest to youngest. |
| [*].age | sum(@) | returns the sum of all ages. |
Pour évaluer ces phrases, je recommande d’utiliser un récepteur Voir les résultats du arbre et de l’utiliser dans le mode JSON JMESPath Tester. Introduisez la phrase dans le champ Expression JMESPath, puis cliquez sur le bouton Tester.
Conclusion #
JMESPath est un outil très puissant pour extraire des valeurs, plusieurs valeurs, l’évaluation ou la mise en œuvre de fonctions à partir des valeurs qui satisfont une ou plusieurs critères, toujours n’oubliez pas d’exercer avant de développer votre phrase ou expression. Il est toujours bon de vérifier les critères avec différentes types de réponses pour obtenir des résultats conclusifs. Vous devez pratiquer jusqu’à la prochaine fois!