

Extracteur XPath
Sommaire
intermédiaire - This article is part of a series.

Qu’est-ce que XPath? #
XPath est une langue de requête utilisée pour trouver et sélectionner des informations spécifiques dans les documents XML. Sa syntaxe est basée sur le notation de chemin utilisé dans les systèmes de fichiers, ce qui rend facile à apprendre et à utiliser pour ceux qui sont familiers avec cette notation. La histoire d’XPath est étroitement liée au développement du XML. XPath a été développé par la Conseil Mondial de l’Internet (W3C) comme partie intégrante de la spécification XSLT (Langage Extensible Stylesheet pour la Transformation), qui a été publiée en novembre 1999. La XSLT est un langage utilisé pour transformer les documents XML en formats autres, tels que HTML ou du texte pur.
XPath a été conçu pour permettre aux développeurs d’accéder à des informations spécifiques dans les documents XML et de fournir une façon efficace de rechercher et sélectionner des éléments et des attributs. XPath est largement utilisé dans les applications qui travaillent avec XML, comme les processus de transformation XSLT, les navigateurs web et les systèmes de gestion des bases de données qui utilisent XML pour stocker et récupérer du data. Son syntaxe simple et sa capacité à sélectionner précisément le data lui rendent un outil puissant et versatile pour analyser et manipuler le data.
Qu’est-ce que l’XML ?
XML est pour Langage de Marqueurs Élargissable (Langage de Marqueurs Élargissable). Il sert à créer des documents structurés. XML a été créé comme une norme pour les documents créés qui peuvent être lus par les humains et par les systèmes informatiques. L’histoire d’XML remonte aux années 1990, lorsque le Web World a commencé à se populariser et qu’il était nécessaire de créer un langage de marqueurs qui permettait la création de documents structurés et pouvait être interprété par différents systèmes et applications. À cette époque, le langage de marqueurs le plus couramment utilisé était HTML, mais cela ne suffisait pas pour les besoins de l’époque. En 1996, la World Wide Web Consortium (W3C) a initié un projet visant à créer un langage de marqueurs qui pouvait être utilisé pour tous types de documents. Ce projet était dirigé par Jon Bosak, qui suggéra le nom XML et conçut la syntaxe du langage. XML a été officiellement présentée en février 1998 et a été adopté rapidement comme une norme par l’industrie.
Depuis lors, l’XML a été utilisé dans une variété de applications, notamment la représentation de données sur les applications basées sur le web, la communication entre systèmes hétérogènes et la création de documents structurés dans divers secteurs tels que l’édition des livres et la publication scientifique. L’XML a évolué au fil du temps et de nouvelles extensions et outils ont été créés pour sa utilisation.
<?xml version="1.0" encoding="UTF-8"?>
<book>
<title>El guardián entre el centeno</title>
<author>J.D. Salinger</author>
<publisher>Alianza Editorial</publisher>
<year>1951</year>
<genre>Ficción</genre>
<price>10.99</price>
</book>
Comment fonctionne XPath dans JMeter? #
Dans JMeter, l’extracteur XPath est un Post-Processor qui vous permet de récupérer des valeurs spécifiques d’une réponse XML. Pour cela, nous devons suivre ces étapes :
- Ajoutez un élément HTTP Request ou Sampler Simultané à votre plan de test JMeter pour effectuer une requête HTTP et recevoir une réponse XML.
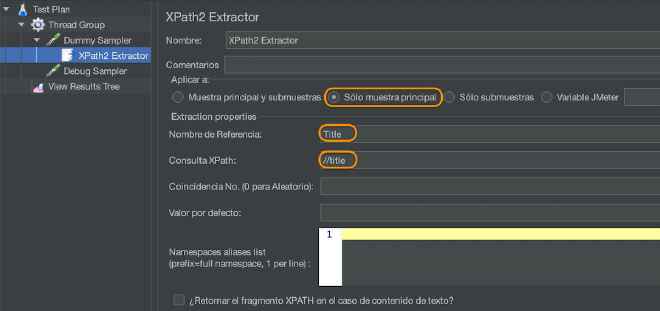
- Ajoutez un extracteur XPath ou XPath2 Extractor à l’élément mentionné ci-dessus, qui sera responsable de récupérer des valeurs spécifiques d’une réponse XML.
- Configurez les champs requis dans le post-processor XPath ou XPath2 Extractor en suivant la table suivante :
| Propriété | Décrépagement | Obligatoire |
|---|---|---|
| Nom | Descriptive name for this element that is displayed in the tree. | Non |
| Appliquer à | Utile lorsque utilisé avec les mappers qui peuvent générer des sous-samples, tels que l’HTTP sampler avec des ressources embedées, le Lecteur de Mail ou un contrôleur de transaction générés. Sous-sample uniquement: s’applique uniquement à la sous-sample Sous-samples uniquement: s’applique uniquement aux sous-samples Main et sous-samples: s’applique à tous les deux Nom de variable utilisé dans JMeter: l’extraction sera appliquée au contenu du nom de la variable. Le match XPath est appliqué à toutes les épreuves qui qualifient, et tous les résultats correspondants seront renvoyés.< | Oui |
| Retourner le fragment XPath complet en lieu de texte? | Si sélectionné, retourne le fragment au lieu du texte. Par exemple, //title retourne “<title>Apache JMeter</title>” au lieu de “Apache JMeter”. Ainsi, //title/text() retourne “Apache JMeter”. | Non |
| Nom de la variable créée | Le nom de la variable dans JMeter où le résultat sera stocké. | Oui |
| Requête XPath | La requête d’élément en utilisant l’anglais XPath 2.0 langage. Peut retourner plusieurs résultats. | Oui |
| Nombre de Matches (0 pour aléatoire) | Si la requête XPath a beaucoup de résultats, vous pouvez choisir quelles à extraire comme variables: 0: signifie aléatoire (par défaut) -1: signifie extraire tous les résultats, seront nommés par <variable name>_N (où N est de 1 à le nombre de résultats) X: signifie extraire le résultat X (si X est plus grand que le nombre de matches, rien ne sera retourné. La valeur par défaut sera utilisée). | Non |
| Valeur par défaut | Valeur par défaut retournée lorsque aucune correspondance n’est trouvée. De même retourne si la node n’a pas de valeur et option pour fragment non sélectionné. | Non |
| Liste des alias namespaces | Liste d’alias que vous voulez utiliser pour analyser le document, une ligne par déclaration. Vous devez spécifier-les comme prefix=namespace. Cette implémentation facilite l’utilisation des noms de namespace en comparaison avec la version précédente du XPathExtractor. | Non |
<?xml version="1.0" encoding="UTF-8"?>
<book>
<title>El guardián entre el centeno</title>
<author>J.D. Salinger</author>
<publisher>Alianza Editorial</publisher>
<year>1951</year>
<genre>Ficción</genre>
<price>10.99</price>
</book>
Nous pouvons extraire les valeurs suivantes à l’aide de XPath :
/book/title //El guardián entre el centeno
/book/author //J.D. Salinger
/book/publisher //Alianza Editorial
/book/year //1951
/book/genre //Ficción
/book/price //10.99
Qu’est-ce qu’une requête XPath ? #
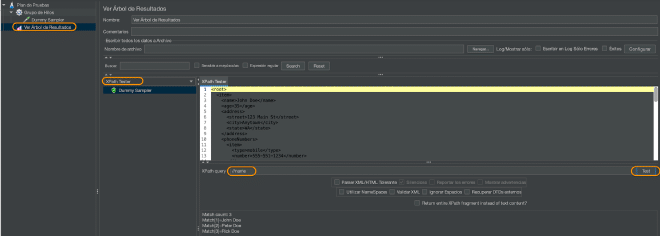
Une requête XPath est une expression écrite dans le langage XPath qui est utilisée pour sélectionner des nœuds spécifiques d’un document XML. Les expressions XPath sont composées de séquences de pas de navigation qui spécifient comment naviguer dans le document XML et sélectionner les nœuds désirés. Par exemple, une requête XPath simple comme //title sélectionne tous les nœuds title dans le document XML, tandis qu’une requête plus complexe comme //book[@category=‘science’]/title sélectionne seulement les titres des livres qui appartiennent à la catégorie science.
Quels autres exemples d’utilisation pourraient avoir l’extracteur XPath ? #
Assumez que nous considérons un exemple plus complexe comme suit :
<root>
<item>
<name>John Doe</name>
<age>35</age>
<address>
<street>123 Main St</street>
<city>Anytown</city>
<state>WA</state>
</address>
<phoneNumbers>
<item>
<type>mobile</type>
<number>555-551-1234</number>
</item>
<item>
<type>home</type>
<number>555-552-5678</number>
</item>
</phoneNumbers>
<email>john.doe@example.com</email>
</item>
<item>
<name>Peter Doe</name>
<age>34</age>
<address>
<street>123 Second St</street>
<city>RacconCity</city>
<state>TX</state>
</address>
<phoneNumbers>
<item>
<type>mobile</type>
<number>555-553-1234</number>
</item>
<item>
<type>home</type>
<number>555-554-5678</number>
</item>
</phoneNumbers>
<email>peter.doe@example.com</email>
</item>
<item>
<name>Rick Doe</name>
<age>36</age>
<address>
<street>123 Third St</street>
<city>Springfield</city>
<state>NJ</state>
</address>
<phoneNumbers>
<item>
<type>mobile</type>
<number>555-555-1234</number>
</item>
<item>
<type>home</type>
<number>555-556-5678</number>
</item>
</phoneNumbers>
<email>rick.doe@example.com</email>
</item>
</root>
For this example, suppose we want to evaluate and extract the following data:
| Expression XPath | result |
|---|---|
| //name | Tous les éléments de nom John Doe, Peter Doe, Rick Doe. |
| //item[1]/name | L’élément de nom du premier objet John Doe. |
| //item[2]/age | La propriété d’âge du deuxième objet 34. |
| //item[3]/email | La propriété d’email du troisième objet rick.doe@example.com |
| //item[1]/address/street | L’élément de rue du premier objet 123 Main St. |
| //item[2]/address/city | La propriété de la ville du deuxième objet RacconCity. |
| //item[3]/address/state | La propriété du statut du troisième NJ objet d’adresse. |
| //item[2]/phoneNumbers/item[type=‘mobile’]/number | Les numéros mobiles de la deuxième objet 555-551-1234, 555-553-1234, 555-555-1234. |
| //item[3]/phoneNumbers/item[type=‘home’]/number | Les numéros fixes de la troisième objet 555-556-5678. |
| //phoneNumbers/item[type=‘mobile’]/number | Tous les numéros mobiles 555-551-1234, 555-553-1234, 555-555-1234. |
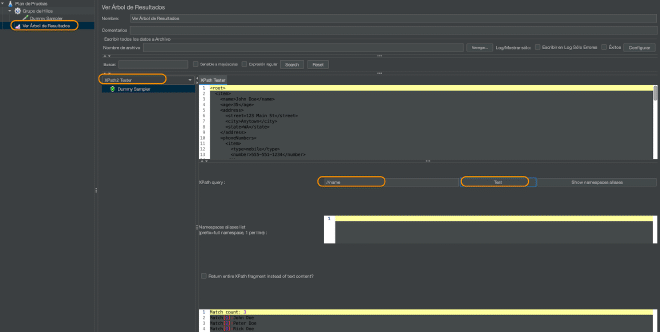
| count(/root/item) | Le nombre d’objets 3. |
| sum(//age) | La somme de tous les âges 105. |
| //name | //email | Tous les noms et adresses email. |
| (//phoneNumbers/item[type='mobile']/number)[1] | Le premier numéro mobile 555-551-1234. |
| (//phoneNumbers/item[type='home']/number)[2] | Le deuxième numéro fixe. |
| //*[starts-with(name(), 'a')] | Retourne les champs qui commencent par la lettre a. |
| //phoneNumbers/item[starts-with(type, 'h')]/number | Retourne les numéros de téléphone dont le type commence par h - home. |
| /root/item[not(starts-with(email, 'john'))]/email | Tous les emails qui ne commencent pas par John. |
Pour évaluer ces statements, je recommande d’utiliser un récepteur de résultats View results tree et d’utiliser la vue dans XPath Tester et d’entrer le statement dans le champ Expression XPath et cliquer sur le bouton Test.
Qu’est-ce que XPath 2 dans JMeter ? #
Dans JMeter, XPath 2 est implémenté via la bibliothèque Saxon, qui est une version de XPath 2 et XSLT 2. À partir de la version 5 de JMeter, nous n’avons plus besoin d’utiliser XPath 2. La principale différence entre XPath et XPath 2 dans JMeter est que XPath 2 est une version plus récente du langage de requêtes XPath et offre des fonctionnalités supplémentaires non disponibles dans la version précédente. Un des améliorations significatifs de XPath 2 est le support pour les types de données complexes, ce qui permet d’effectuer des requêtes sur des données structurées plus efficacement. XPath 2 également fournit une série de fonctions supplémentaires pour manipuler et transformer les données, telles que la tri et l’organisation des résultats de la requête.
| XPath 2 Expression | result |
|---|---|
| //item[position() = 1] | Sélectionne l’élément item de la première fois. |
| //phoneNumbers/item[type = ‘home’]/number | Sélectionne le numéro de téléphone provenant des éléments qui ont une attribut type égal à home. |
| //address[state = ‘WA’]/city | Sélectionne la ville provenant des adresses qui ont un attribut state égal à WA. |
| //item[ends-with(email, ’example.com’)]/name | Sélectionne le nom de tous les éléments item dont l’adresse email termine par example.com. |
| //item[phoneNumbers/item[number = ‘555-553-1234’]]/address/street | Sélectionne la rue provenant des items ayant un numéro de téléphone égal à 555-553-1234. |
| //item[name = ‘Peter Doe’]/address/city | Sélectionne la ville provenant de l’adresse de l’élément item avec le nom Peter Doe. |
| //phoneNumbers/item[matches(number, ‘.*1234’)]/type | Sélectionne le type de tous les éléments dont le numéro de téléphone contient la séquence 1234. |
| //item[age >= 35]/name | Sélectionne le nom de tous les éléments dont l’âge est supérieur ou égal à 35. |
| //item[not(address/state = ‘TX’)]/email | Sélectionne l’email pour tous les éléments dont la statut n’est pas TX. |
| //item[phoneNumbers/item[type = ‘home’] and phoneNumbers/item[type = ‘mobile’]]/email | Sélectionne l’email pour les téléphones ayant un type égal à home ou mobile. |
Conclusion #
XPath 2 Extrayseur est un outil très puissant pour extraire des valeurs, plusieurs valeurs, des évaluations ou une exécution de fonctions à partir des valeurs afin d’atteindre un ou plusieurs critères. Remarquez toujours que la pratique doit être faite avant de développer votre phrase ou expression. Il est bon de vérifier les critères avec différentes types de réponses pour obtenir des résultats conclusifs. La pratique est nécessaire, jusqu’à la prochaine fois!