Ejecución de JMeter distribuido (AWS Fargate + Docker)
Table of Contents
Avanzado - This article is part of a series.

Con este artículo damos por concluida la serie de JMeter distribuido, en esta ocasión utilizando contenedores. Existen muchas vertientes de esta modalidad, pues podriamos utilizar una gran variedad de plataformas de administración y orquestación de contenedores basada en Kubernetes como:
- Amazon Elastic Kubernetes Service (EKS)
- Azure Kubernetes Service (AKS)
- Google Kubernetes Engine (GKE)
- Rancher, etc.
También podemos utilizar las versiones no basadas en Kubernetes como:
- Amazon Elastic Container Service (ECS)
- Azure Container Instances (ACI)
- Google Cloud Run, etc.
Para este ejemplo en particular utilizaremos la solución AWS Elastic Container Service (ECS) con el servicio Fargate.
¿ Cuando sería prudente realizar el esfuerzo ? #
De igual forma que lo mencioné en las publicaciones anteriores JMeter distribuido local y JMeter distribuido publico, te aconsejo utilizar este esquema si tienes la necesidad de realizar una prueba de carga o estrés de entre 8,000 a 25,000 hilos o usuarios virtuales. Esto debido a la inversión en tiempo y esfuerzo para habilitar este esquema. Sin lugar a dudas esta modalidad se puede expandir mucho más allá de 25k hilos. Pero te recomiendo utilizar EC2 en lugar de Fargate y solicitar apoyo para monitorear las instancias y resultados en tiempo real.
¿ Cómo funciona ? #
Esta arquitectura ya no funciona en la modalidad maestro-esclavo. La razón principal es que el mecanismo de comunicación entre maestro y esclavos RMI, no es muy eficiente en grandes volúmenes y pudiera generarnos un cuello de botella (irónico). Cada uno de los contenedores en ejecución será un generador de carga, y para generar la imagén del contenedor, nos basaremos en el flujo alterno de la guía JMeter + Docker.
Una vez que la imagen se encuentre disponible en el repoistorio de AWS, podremos definir una tarea ligada a esa imagen. Para posteriormente ejecutarla, la ejecución se realizará por medio de Fargate y podremos escalar hasta 50 tareas como máximo. Pero recordemos que cada una de las tareas sería un contenedor en ejecución o un generador de carga, tendríamos 50 generadores de carga disponibles.
Al finalizar la ejecución, los archivos de resultados JTL y bitácora de JMeter serán copiados a S3, para que puedas descargarlos, procesarlos o archivarlos como evidencia de la ejecución. Aquí puedes encontrar un ejemplo similar al que vamos a seguir acontinuación pero es por medio de línea de comandos y se encuentra en idioma inglés.
Receta de cocina #
1.- Clonar el repositorio #
Primero necesitamos clonar el siguiente repositorio, para obtener los archivos necesarios para contruir nuestra imagen Docker:
git clone https://github.com/daeep/JMeter_Docker_AWS.git
cd JMeter_Docker_AWS
2.- Generar el IAM role #
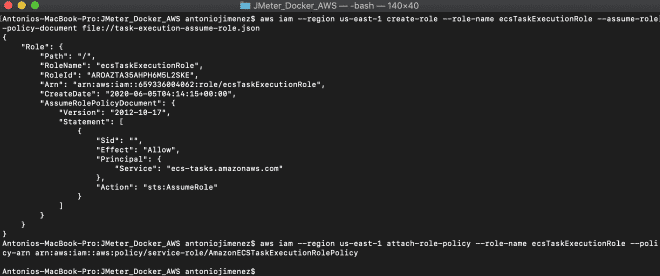
Vamos a generar un rol especifico para ejecutar las tareas en Fargate, este rol se llama ecsTaskExecutionRole. El rol se puede generar por medio de línea de comandos o por la consola de administración. Les recomiendo instalar y configurar la interfáz de línea de comandos de AWS CLI para crear este rol utilizando el archivo task-execution-assume-role.json que se encuentra incluido en el repositorio que descargamos.
aws iam --region us-east-1 create-role --role-name ecsTaskExecutionRole --assume-role-policy-document file://task-execution-assume-role.json
aws iam --region us-east-1 attach-role-policy --role-name ecsTaskExecutionRole --policy-arn arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy
Como puedes observar estoy trabajando en la región Virginia us-east-1.
3.- Agregar el S3 Bucket y credenciales AWS en el archivo Docker #
Debemos modificar y adecuar nuestro archivo Dockerfile, que se encuentra dentro de la carpeta JMeter_Docker_AWS. Este proyecto contempla guardar los archivos de resultados en S3, aunque también pudieramos guardar los resultados en InfluxDB o ElastiSearch, para ser consumidos por Grafana o Kibana respectivamente. Para guardar los archivos de resultados en S3, necesitamos crear un bucket e incluir nuestras credenciales en las líneas 18-20 del Dockerfile, estas credenciales pueden ser las mismas que utiliza el AWS CLI, si es que le otorgaste permisos de administrador.
18 ENV AWS_ACCESS_KEY_ID #####################
19 ENV AWS_SECRET_ACCESS_KEY #################
20 ENV AWS_DEFAULT_REGION #################### <-- puede ser la región (us-east-1)
Por último tenemos que modificar las líneas 53 y 54 con el nombre del bucket en donde se guardarán los archivos. Aquí te dejo una guía en español para crear buckets. En caso de no querer guardar el archivo de resultados JTL y la bitácora de JMeter LOG, tendrías que borrar las líneas 18-20 y 49-54. Pero no se los recomiendo.
53 && aws s3 cp ${JMETER_HOME}/result-${PUBLIC_IP}-${LOCAL_IP}.jtl s3://nombre-del-bucket/ \
54 && aws s3 cp ${JMETER_HOME}/jmeter-${PUBLIC_IP}-${LOCAL_IP}.log s3://nombre-del-bucket/
4.- Compilar el archivo Docker #
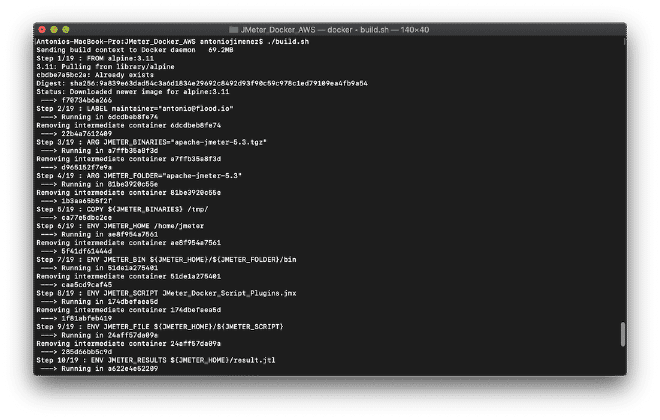
Vamos a compilar nuestra imagen antes de empujarla al repositorio, podemos realizar la construcción ejecutando el shell script ./build.sh que se encuentra en nuestra carpeta o también con el comando: docker build -t jmeter-docker ., esto es muy similiar al flujo alterno de la publicación JMeter + Docker. De igual forma este proyecto esta preparado para construir la imagen con nuestros binarios locales, pero ahora se copiará el script JMX a dentro del contenedor (modificar línea 13). En caso de necesitar archivos de soporte como CSV o imágenes deberás agregarlos de manera similar a las líneas 11, 13, 14 y 17.
11 ENV JMETER_HOME /home/jmeter <-- Carpeta local interna
...
13 ENV JMETER_SCRIPT JMeter_Docker_Script_Plugins.jmx <-- Nombre de tu script local
14 ENV JMETER_FILE ${JMETER_HOME}/${JMETER_SCRIPT} <-- Archivo final interno
...
17 COPY ${JMETER_SCRIPT} ${JMETER_FILE} <-- Copia el archivo local dentro del contenedor
5.- (Opcional) Si necesitas más memoria #
Una vez compilada nuestra imagen, podemos ejecutarla localmente para validar que efectivamente funciona. Para ello puedes alternar las líneas 21 o 22, que contienen diferentes valores de JVM_ARGS. Cabe mencionar que este script se encuentra parametrizado siguiendo las instrucciones descritas aquí. Recuerda volver a compilar antes de ejecutar si modificaste este valor y finalmente para lanzarlo podemos utilizar el shell script ./run.sh.
21 ENV JVM_ARGS="-Xms2048m -Xmx4096m -XX:NewSize=1024m -XX:MaxNewSize=2048m -Duser.timezone=UTC" <-- Suficiente para algunos cientos de usuarios concurrentes
22 ENV JVM_ARGS "-Xms256m -Xmx1024m -XX:NewSize=256m -XX:MaxNewSize=1024m -Duser.timezone=UTC" <-- Suficiente para algunas decenas de usuarios concurrentes
6.- Crear el repositorio ECS y subir la imagen docker #
Seguimos adelante creando un repositorio en AWS ECS, no es complicado. Pero igual puedes consultar los pasos aquí, una vez que tengas el repositorio listo. Vamos a subir la imagen, con los siguientes comandos:
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin 659336004062.dkr.ecr.us-east-1.amazonaws.com
docker tag jmeter-docker:latest 659336004062.dkr.ecr.us-east-1.amazonaws.com/jmeter-docker:latest
docker push 659336004062.dkr.ecr.us-east-1.amazonaws.com/jmeter-docker:latest
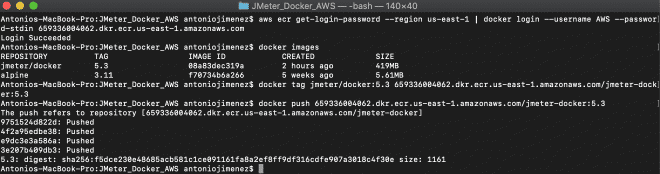
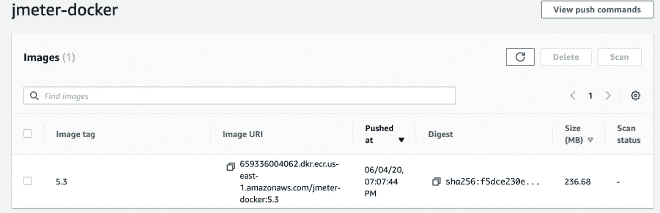
7.- Cluster en Fargate #
Ahora vamos a crear un cluster Fargate, creo que se pueden reproducir los pasos con solo seguir las imágenes.
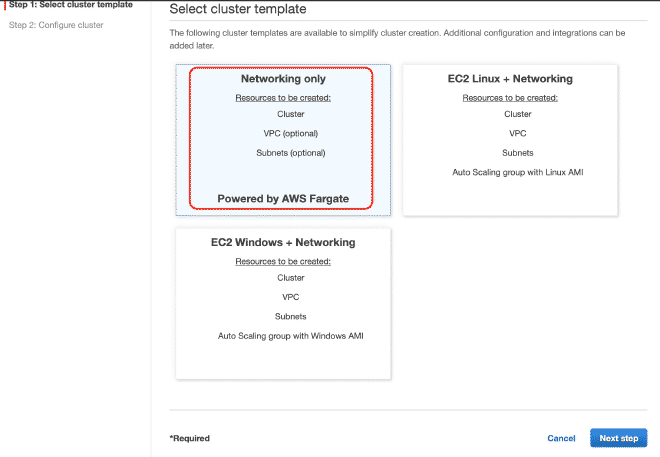
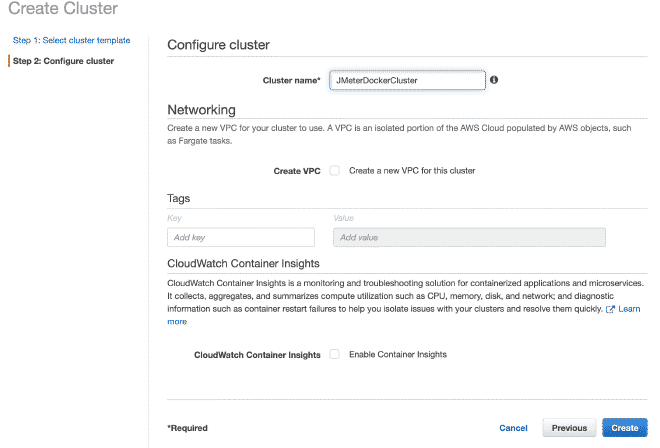

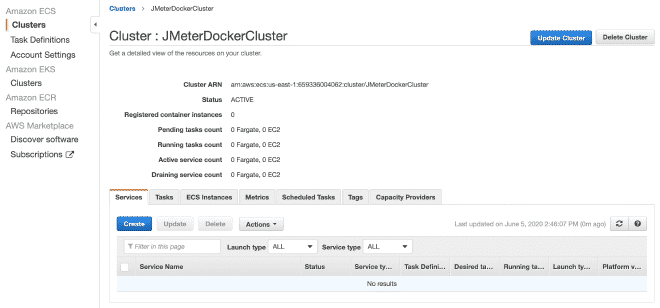
8.- Definición de tareas en Fargate #
Posteriormente vamos a definir una nueva tarea, también creo que es posible continuar sólo con imágenes.
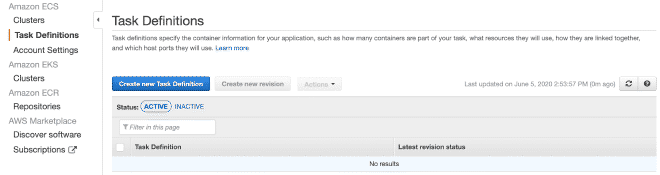
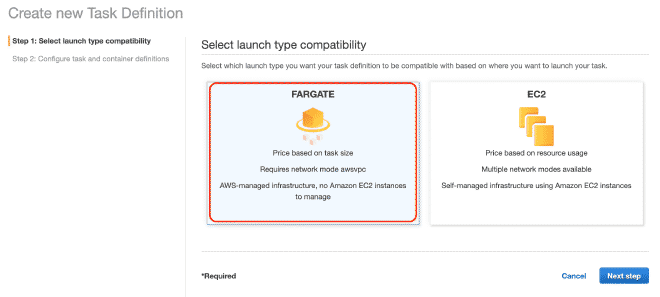
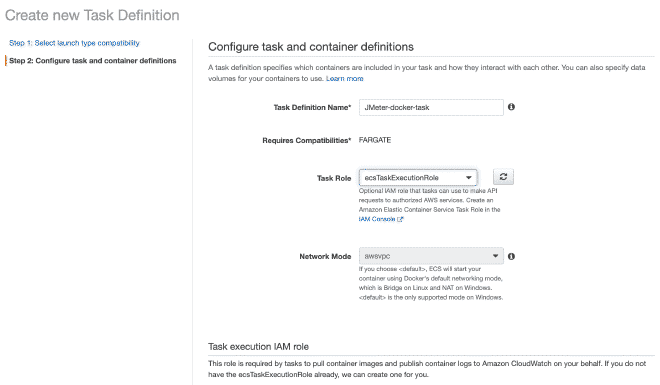
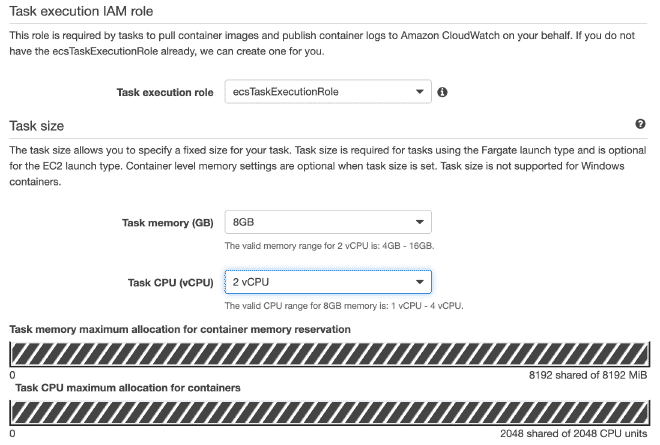
Recuerda que los valores para CPU y Memoria, así como el límite suave de memoria son configurables y te recomiendo empezar con pocos hilos para no acabarse los recursos rápidamente y la prueba falle.
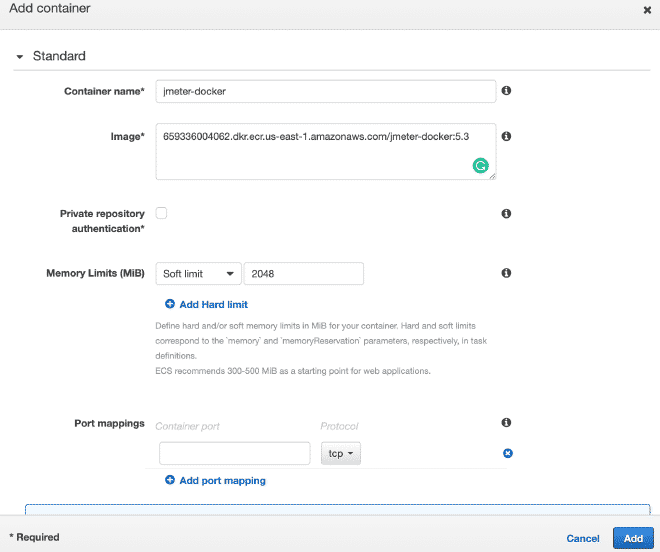
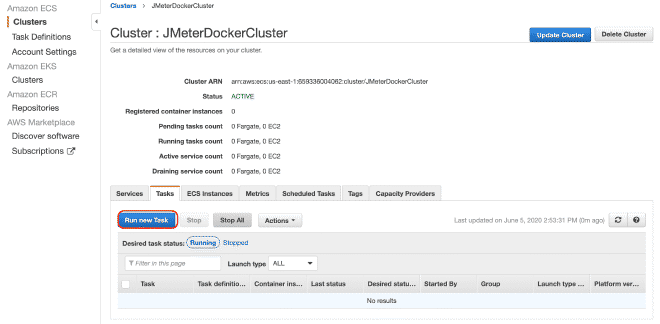
9.- Ejecución de las Tareas #
Por finalizar, vamos a ejecutar la(s) tarea(s) dentro de nuestro Cluster, el máximo permitido son 10 tareas por Cluster. Si queremos ejecutar más tareas, necesitaremos generar más clusters. La ventaja es que latarea ya está definida, será muy sencillo ejecutarla en múltiples clusters. Tengo entendido que límite son 50 tareas en total, en otras palabras 5 clusters ejecutando 10 tareas máximo, pero también se puede solicitar incrementos en los límites, aunque si requerimos más capacidad de cómputo te recomendaría utilizar EC2 en lugar de Fargate.
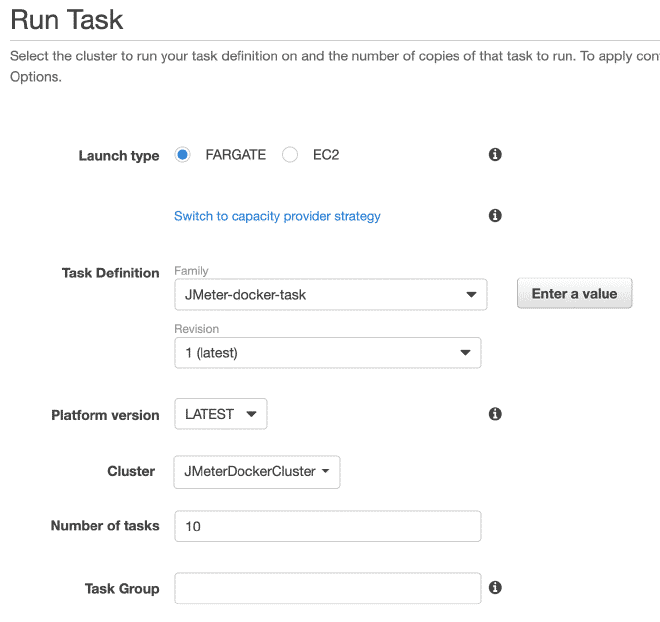
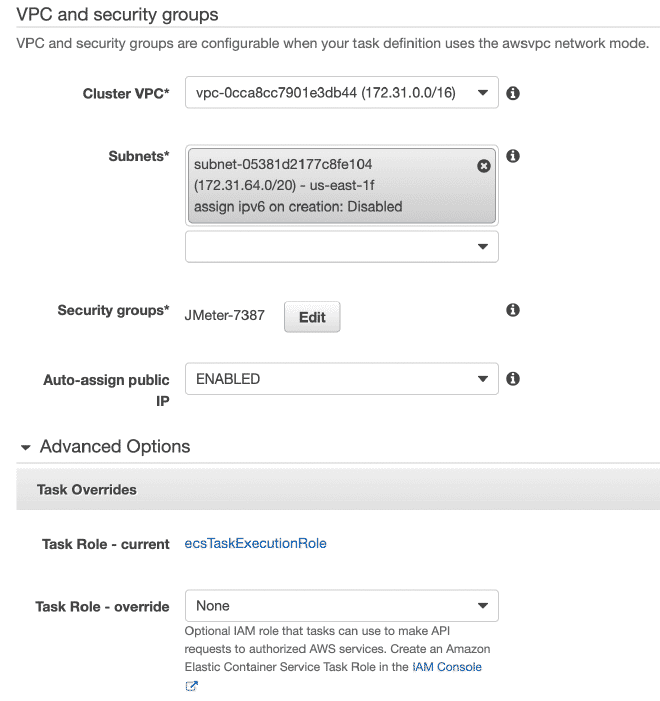
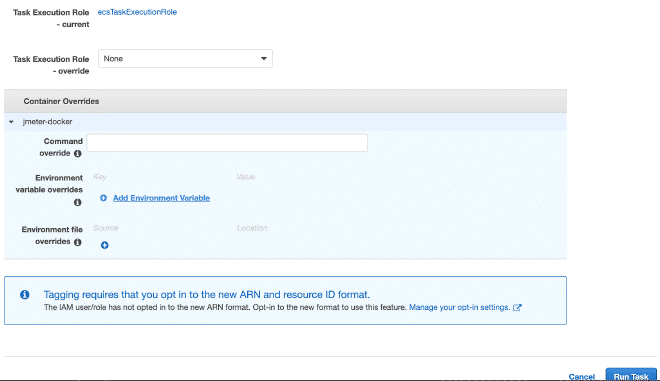
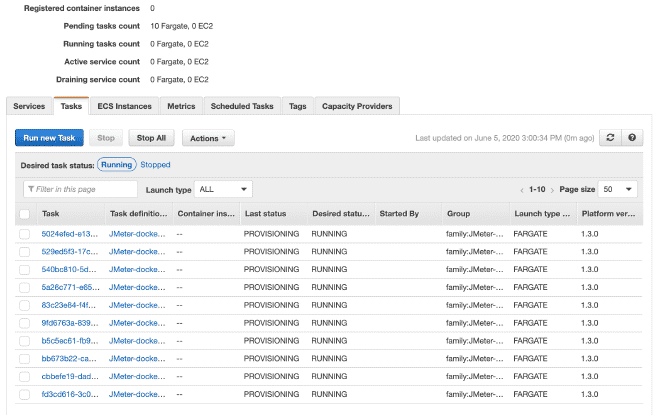
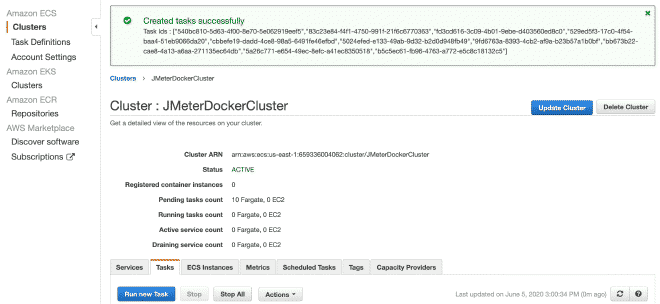
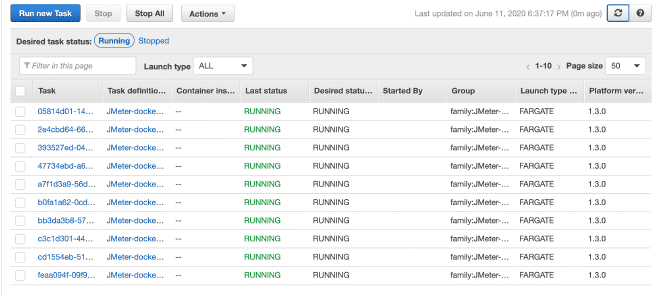
En la sección de ejecución de la tarea podemos definir variables de entorno, por lo que si queremos sobre escribir o anular alguna variables como usuarios, rampa o duración, aquí podemos hacerlo.
Conclusión #
Entiendo que son muchos pasos y que puedan sonar difíciles, sobre todo si eres nuevo en AWS o ECS. Justamente por ese motivo decidí publicar la sección de Docker antes de explicar la sección de AWS, espero que mi esfuerzo para simplificar el contenido les ayude a reproducirlo. Está solución es sumamente versátil y podrián utilizar cualquier otra plataforma de orquestación de contenedores para la ejecución y obtener resultados similares. Cabe mencionar que pudimos resolver algunas secciones con archivos Docker compose o ec2_param en formato YAML en línea de comandos, pero la intención era simplificar el contenido. Espero puedan replicar este esquema y no duden en contactarnos si necesitan nuestra ayuda.
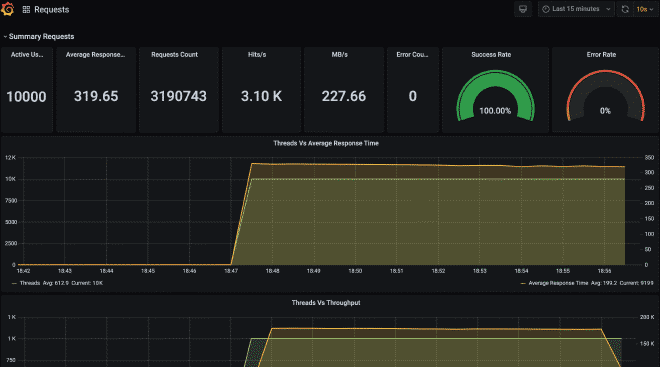
Por último les dejo como se verían los archivos en S3 y el dashboard de Grafana con la información de está ejecución.
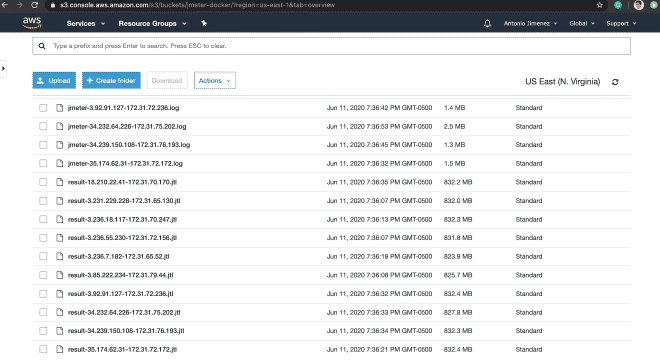
https://jmeter-docker.s3.amazonaws.com/result-35.174.62.31-172.31.72.172.jtl