
XPath Extractor
Table of Contents
Intermedio - This article is part of a series.

¿ Qué es XPath ? #
XPath es un lenguaje de consulta utilizado para buscar y seleccionar información específica en documentos XML. La sintaxis de XPath se basa en la notación de ruta de acceso (path) utilizada en los sistemas de archivos, lo que lo hace fácil de aprender y utilizar para aquellos familiarizados con dicha notación. La historia de XPath está estrechamente relacionada con la de XML. XPath fue desarrollado por el World Wide Web Consortium (W3C) como parte de la especificación de XSLT (Extensible Stylesheet Language Transformations), que se publicó en Noviembre de 1999. XSLT es un lenguaje utilizado para transformar documentos XML en otros formatos, como HTML o texto plano.
XPath fue diseñado para permitir a los desarrolladores acceder a información específica en documentos XML y para proporcionar una forma eficiente de buscar y seleccionar elementos y atributos. XPath es ampliamente utilizado en aplicaciones que trabajan con XML, como los procesadores de transformación XSLT, los navegadores web y los sistemas de gestión de bases de datos que utilizan XML para almacenar y recuperar información. Su sintaxis simple y su capacidad para seleccionar datos de manera precisa lo hacen una herramienta poderosa y versátil para el análisis y manipulación de datos.
¿ Qué es XML ? #
XML es el acrónimo de eXtensible Markup Language (Lenguaje de Marcado Extensible). Es un lenguaje de marcado que se utiliza para la creación de documentos estructurados. XML fue creado para ser un estándar para la creación de documentos que pudieran ser leídos tanto por humanos como por máquinas. La historia de XML se remonta a los años 90, cuando la World Wide Web empezaba a popularizarse y se hacía necesario un lenguaje de marcado que permitiera la creación de documentos estructurados y que pudieran ser interpretados por diferentes sistemas y aplicaciones. En ese momento, el lenguaje de marcado más utilizado era HTML, pero éste no era suficiente para las necesidades de la época. En 1996, el World Wide Web Consortium (W3C) inició un proyecto para crear un lenguaje de marcado que pudiera ser utilizado para cualquier tipo de documento. Este proyecto fue liderado por Jon Bosak, quien propuso el nombre XML y diseñó la sintaxis del lenguaje. XML fue presentado oficialmente en febrero de 1998 y fue adoptado rápidamente como estándar por la industria.
Desde entonces, XML ha sido utilizado en una gran variedad de aplicaciones, incluyendo la representación de datos en aplicaciones web, la comunicación entre sistemas heterogéneos y la creación de documentos estructurados en diferentes industrias, como la edición de libros y publicaciones científicas. XML ha evolucionado con el tiempo y se han creado diversas extensiones y herramientas para su uso.
Ejemplo:
<?xml version="1.0" encoding="UTF-8"?>
<book>
<title>El guardián entre el centeno</title>
<author>J.D. Salinger</author>
<publisher>Alianza Editorial</publisher>
<year>1951</year>
<genre>Ficción</genre>
<price>10.99</price>
</book>
¿ Cómo funciona XPath en JMeter ? #
En JMeter, XPath Extractor es un Post-procesador que permite extraer valores específicos de una respuesta XML. Para ello debemos seguir los siguientes pasos:
- Agregue un elemento HTTP Request o Dummy Sampler a su plan de prueba de JMeter para realizar una solicitud HTTP y recibir una respuesta XML.
- Agregue un extractor XPath o XPath2 Extractor al elemento antes mencionado, este extractor se encargará de extraer los valores específicos que se necesitan de la respuesta XML.
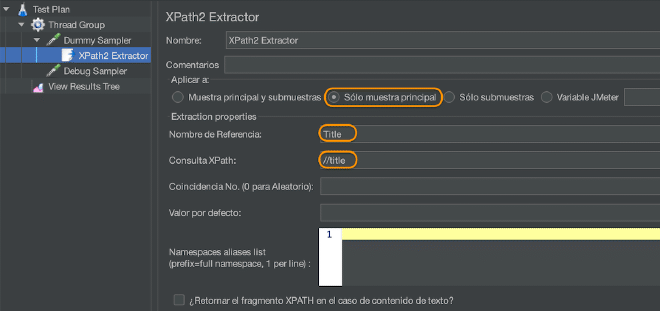
- Configure los campos requeridos en el post-procesador XPath o XPath2 Extractor como se muestra en la siguiente tabla:
| Atributo | Descripción | Requerido |
|---|---|---|
| Nombre | Nombre descriptivo para este elemento que se muestra en el árbol. | No |
| Aplicar a | Útil para su uso con muestreadores que pueden generar sub-muestras, como el muestreador HTTP con recursos incrustados, Mail Reader o las muestras generadas por el controlador de transacciones. Muestra principal solamente: solo se aplica a la muestra principal Solo sub-muestras: solo se aplica a las sub-muestras Muestra principal y sub-muestras: se aplica a ambas Nombre de la variable JMeter a utilizar: la extracción se aplicará al contenido de la variable nombrada. La coincidencia de XPath se aplica a todas las muestras que califiquen en orden, y se devolverán todos los resultados que coincidan. | Sí |
| ¿Devolver el fragmento XPath completo en lugar del contenido de texto? | Si se selecciona, se devolverá el fragmento en lugar del contenido de texto. Por ejemplo, //title devolvería “<title>Apache JMeter</title>” en lugar de “Apache JMeter”. En este caso, //title/text() devolvería “Apache JMeter”. | No |
| Nombre de la variable creada | El nombre de la variable JMeter en la que se almacenará el resultado. | Sí |
| XPath Query | Consulta de elemento en el lenguaje XPath 2.0. Puede devolver más de una coincidencia. | Sí |
| Número de coincidencias (0 para aleatorio) | Si la consulta de ruta XPath tiene muchos resultados, puedes elegir cuál(es) extraer como variables: 0: significa aleatorio (valor predeterminado) -1: significa extraer todos los resultados, se llamarán como <nombre de la variable>_N (donde N va de 1 al número de resultados) X: significa extraer el resultado X (enésimo). Si este X (enésimo) es mayor que el número de coincidencias, no se devuelve nada. Se utilizará el valor predeterminado | No |
| Valor predeterminado | Valor predeterminado devuelto cuando no se encuentra ninguna coincidencia. También se devuelve si el nodo no tiene valor y no se selecciona la opción de fragmento. | No |
| Lista de alias de espacios de nombres | Lista de alias de espacios de nombres que deseas utilizar para analizar el documento, una línea por declaración. Debes especificarlos como prefix=namespace. Esta implementación facilita el uso de espacios de nombres en comparación con la versión anterior de XPathExtractor. | No |
Ejemplo:
<?xml version="1.0" encoding="UTF-8"?>
<book>
<title>El guardián entre el centeno</title>
<author>J.D. Salinger</author>
<publisher>Alianza Editorial</publisher>
<year>1951</year>
<genre>Ficción</genre>
<price>10.99</price>
</book>
Podemos utilizar la siguiente expresión XPath para extraer estos valores:
/book/title //El guardián entre el centeno
/book/author //J.D. Salinger
/book/publisher //Alianza Editorial
/book/year //1951
/book/genre //Ficción
/book/price //10.99
¿ Qué es XPath Query ? #
XPath query (o consulta XPath) es una expresión escrita en el lenguaje XPath que se utiliza para seleccionar nodos específicos de un documento XML. Las expresiones XPath se componen de una serie de pasos de ubicación que especifican cómo navegar por el documento XML y seleccionar los nodos deseados. Por ejemplo, una consulta XPath simple como //title seleccionaría todos los nodos title en el documento XML, mientras que una consulta más compleja como //book[@category='science']/title seleccionaría solo los títulos de los libros que pertenecen a la categoría science.
¿ Qué otros ejemplos de uso pudiera tener XPath extractor ? #
Supongamos un ejemplo más complejo, como el siguiente:
<root>
<item>
<name>John Doe</name>
<age>35</age>
<address>
<street>123 Main St</street>
<city>Anytown</city>
<state>WA</state>
</address>
<phoneNumbers>
<item>
<type>mobile</type>
<number>555-551-1234</number>
</item>
<item>
<type>home</type>
<number>555-552-5678</number>
</item>
</phoneNumbers>
<email>john.doe@example.com</email>
</item>
<item>
<name>Peter Doe</name>
<age>34</age>
<address>
<street>123 Second St</street>
<city>RacconCity</city>
<state>TX</state>
</address>
<phoneNumbers>
<item>
<type>mobile</type>
<number>555-553-1234</number>
</item>
<item>
<type>home</type>
<number>555-554-5678</number>
</item>
</phoneNumbers>
<email>peter.doe@example.com</email>
</item>
<item>
<name>Rick Doe</name>
<age>36</age>
<address>
<street>123 Third St</street>
<city>Springfield</city>
<state>NJ</state>
</address>
<phoneNumbers>
<item>
<type>mobile</type>
<number>555-555-1234</number>
</item>
<item>
<type>home</type>
<number>555-556-5678</number>
</item>
</phoneNumbers>
<email>rick.doe@example.com</email>
</item>
</root>
Para este ejemplo, supogamos que deseamos evaluar y extraer los siguiente datos:
| Expresión XPath | resultado |
|---|---|
| //name | Todos los elementos nombre John Doe, Peter Doe, Rick Doe. |
| //item[1]/name | El elemento nombre del primer objeto John Doe. |
| //item[2]/age | La propiedad edad del segundo objeto 34. |
| //item[3]/email | La propiedad email del tercer objeto rick.doe@example.com |
| //item[1]/address/street | La propiedad calle de la dirección del primer objeto 123 Main St. |
| //item[2]/address/city | La propiedad ciudad de la dirección del segundo objeto RacconCity. |
| //item[3]/address/state | La propiedad estado de la dirección del tercer objeto NJ. |
| //item[2]/phoneNumbers/item[type='mobile']/number | El número de teléfono móvil del segundo objeto 555-553-1234. |
| //item[3]/phoneNumbers/item[type='home']/number | El número de teléfono fijo del tercer objeto 555-556-5678. |
| //phoneNumbers/item[type='mobile']/number | Todos los números de teléfono móvil 555-551-1234, 555-553-1234, 555-555-1234. |
| count(/root/item) | El número de objetos 3. |
| sum(//age) | La suma de todas las edades 105. |
| //name | //email | Todos los nombres y correos electrónicos. |
| (//phoneNumbers/item[type='mobile']/number)[1] | El primer número de teléfono móvil 555-551-1234. |
| (//phoneNumbers/item[type='home']/number)[2] | El segundo número de teléfono de casa. |
| //*[starts-with(name(), 'a')] | Devuelve los campos que empiezan con la letra a. |
| //phoneNumbers/item[starts-with(type, 'h')]/number | Devuelve los teléfonos que el tipo empieza con h - home. |
| /root/item[not(starts-with(email, 'john'))]/email | Todos los correos que no inicien con John. |
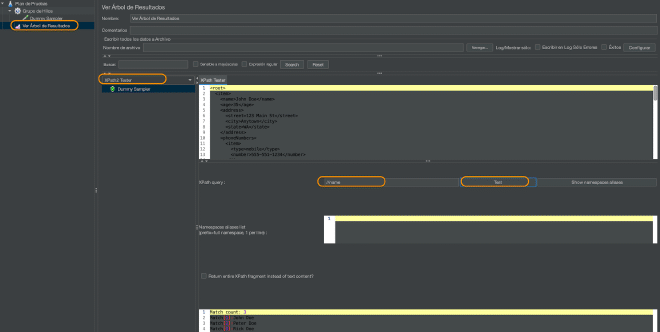
Para evaluar estas sentencias, te recomiendo utilizar un receptor View results tree y utilizar la vista en XPath Tester e introducir la sentencia en el campo XPath Expression y dar click en el boton Test
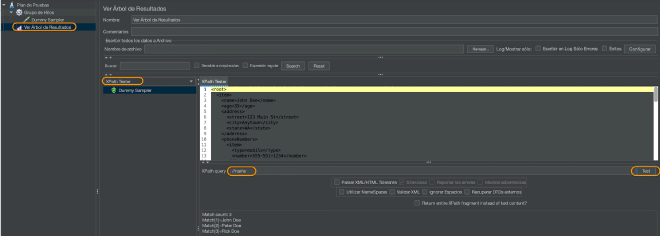
¿ Qué es XPath 2 en JMeter ? #
En JMeter, XPath 2 se implementa utilizando la biblioteca Saxon, que es una implementación de XPath 2 y XSLT 2. Apartir de la versión 5 de JMeter solo debiéramos utilizar XPath 2. La principal diferencia entre XPath y XPath 2 en JMeter es que XPath 2 es una versión más reciente del lenguaje de consulta XPath y ofrece una serie de características adicionales que no están disponibles en la versión anterior. Una de las principales mejoras en XPath 2 es el soporte para tipos de datos complejos, lo que permite trabajar con datos más estructurados en las consultas. XPath 2 también ofrece una serie de funciones adicionales para manipular y transformar datos, como la capacidad de ordenar y agrupar resultados de consulta.
Aqui algunos ejemplos de XPath 2:
| Expresión XPath 2 | resultado |
|---|---|
| //item[position() = 1] | Selecciona el primer elemento item. |
| //phoneNumbers/item[type = 'home']/number | Selecciona el número de teléfono de todos los elementos que tienen un atributo type igual a home. |
| //address[state = 'WA']/city | Selecciona la ciudad de todas las direcciones que tienen un atributo state igual a WA. |
| //item[ends-with(email, 'example.com')]/name | Selecciona el nombre de todos los elementos item cuyo correo electrónico termina con example.com. |
| //item[phoneNumbers/item[number = '555-553-1234']]/address/street | Selecciona la calle de los elementos item con número de teléfono igual a 555-553-1234. |
| //item[name = 'Peter Doe']/address/city | Selecciona la ciudad de la dirección del elemento item que tiene el nombre Peter Doe. |
| //phoneNumbers/item[matches(number, '.*1234')]/type | Selecciona el tipo de todos los elementos cuyo número de teléfono contiene la secuencia 1234. |
| //item[age >= 35]/name | Selecciona el nombre de todos los elementos cuya edad es mayor o igual a 35. |
| //item[not(address/state = 'TX')]/email | Selecciona el correo electrónico de todos los elementos cuyo estado no es TX. |
| //item[phoneNumbers/item[type = 'home'] and phoneNumbers/item[type = 'mobile']]/email | Selecciona el correo electrónico de los teléfonos tipo home o mobile. |
Conclusión #
XPath 2 Extractor es una herramienta muy poderosas para extraer un valor, multiples valores, evaluación o ejecución de funciones de los valores para satisfacer uno o varios criterios, recuerda siempre practicar antes de desarrollar tu sentencia o expression. Siempre es bueno verificar los criterios ante varios tipos de respuestas diferentes para obtener resultados contundentes. Hay que practicar, hasta la próxima!