

Extractor de XPath
Tabela de conteúdos
intermediário - This article is part of a series.

O que é XPath? #
XPath é uma linguagem de consulta usada para encontrar e selecionar informações específicas em documentos XML. A sintaxe do XPath está baseada no notação de caminho usado em sistemas de arquivos, tornando-o fácil de aprender e usar para aqueles que estão familiarizados com essa notação. O histórico do XPath é muito ligado à desenvolvimento de XML. O XPath foi desenvolvido pela World Wide Web Consortium (W3C) como parte da especificação XSLT (Linguagem Extensível para Transformações Stylesheets), que foi publicada em novembro de 1999. XSLT é uma linguagem usada para transformar documentos XML em formatos alternativos, como HTML ou texto plano.
XPath foi projetado para permitir aos desenvolvedores acessar informações específicas em documentos XML e fornecer uma maneira eficiente de procurar e selecionar elementos e atributos. XPath é amplamente utilizado em aplicações que trabalham com XML, como processadores de transformação XSLT, navegadores da web e sistemas de gerenciamento de bases de dados que usam XML para armazenar e recuperar dados. Seu sintaxe simples e capacidade de precisamente selecionar dados o torna um ferramenta poderosa e versátil para analisar e manipular dados.
O que é XML? #
XML significa Linguagem de Marcação Extensível (LME). É uma linguagem de marcapágina usada para criar documentos estruturados. XML foi criado como um padrão para a criação de documentos que poderiam ser lidos tanto por humanos quanto por sistemas e aplicações diferentes. A história do XML remonta ao início dos anos 1990, quando o World Wide Web começou a ganhar popularidade e se tornou necessário ter uma linguagem de marcapágina que permitisse a criação de documentos estruturados e pudesse ser interpretada por sistemas e aplicações diferentes. Naquela época, a linguagem de marcapágina mais comum era HTML, mas não era suficiente para as necessidades do tempo. Em 1996, o World Wide Web Consortium (W3C) iniciou um projeto para criar uma linguagem de marcapágina que pudesse ser usada para qualquer tipo de documento. Este projeto foi liderado por Jon Bosak, que propôs o nome XML e desenhou a sintaxe da linguagem. XML foi oficialmente apresentado em fevereiro de 1998 e foi adotado rapidamente como padrão pela indústria.
Desde então, o XML foi usado em uma variedade de aplicações, incluindo a representação de dados na aplicação web-base, comunicação entre sistemas heterogêneos e a criação de documentos estruturados em diversas indústrias como edição de livros e publicações científicas. O XML evoluiu ao longo do tempo e novas extensões e ferramentas foram criadas para sua utilização.
<?xml version="1.0" encoding="UTF-8"?>
<book>
<title>El guardián entre el centeno</title>
<author>J.D. Salinger</author>
<publisher>Alianza Editorial</publisher>
<year>1951</year>
<genre>Ficción</genre>
<price>10.99</price>
</book>
Como funciona o XPath em JMeter? #
No JMeter, o Extrator de XPath é um Processador Post-Processador que permite você extrair valores específicos de uma resposta XML. Para isso, precisamos seguir estes passos:
- Adicione um elemento HTTP Request ou Sampler Simbólico à sua planilha de teste do JMeter para fazer uma solicitação HTTP e receber uma resposta XML.
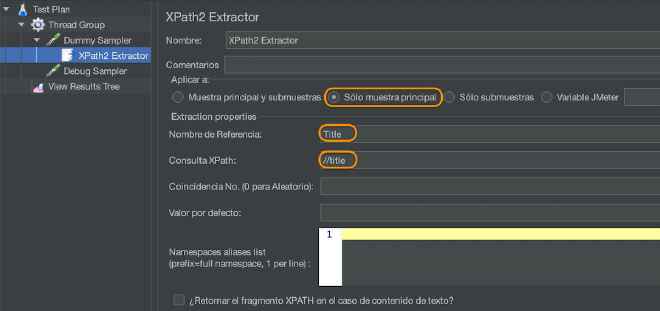
- Adicione um extrator XPath ou XPath2 Extrator ao elemento mencionado acima, que será responsável por extrair valores específicos da resposta XML.
- Configure as campos necessários no post-processor XPath ou XPath2 Extrator conforme mostrado na tabela a seguir:
| Atributo | Descrição | Requerido |
|---|---|---|
| Nome | Descriptive name for this element that is displayed in the tree. | Não |
| Aplicar a este elemento | Ótimo quando usado com mapeadores que podem gerar sub-samplerias, como HTTP sampler com recursos incorporados, leitor de e-mail ou controle de transações gerado por samples. Só para amostras principais: aplica-se apenas à amostra principal Somente para amostras sub-amostras: aplica-se somente às amostras sub-amostras Principais e sub-amostras: aplica-se a ambos Nome da variável criada no JMeter: o resultado será armazenado na variável do JMeter. O fragmento XPath é aplicado a todos os samples que se adequam, e todas as respostas correspondentes serão retornadas.< | Sim |
| Retornar fragmento de XPath em vez de texto? | Se selecionado, retorna o fragmento em vez da textos. Por exemplo, //title retorna “<title>Apache JMeter</title>” em lugar de “Apache JMeter”. Nesse caso, //title/text() retorna “Apache JMeter”. | Não |
| Nome da variável criada | O nome da variável do JMeter onde o resultado será armazenado. | Sim |
| Consulta XPath | Consulta elemento usando a linguagem XPath 2.0. Pode retornar múltiplas respostas. | Sim |
| Número de Respostas (0 para aleatório) | Se a consulta XPath tem muitas respostas, você pode escolher qual será extraída como variáveis: 0: significa aleatório (padrão) -1: significa extração de todas as respostas, será nomeada como <nome da variável>_N (onde N é de 1 a número de resultados) X: significa extração do resultado X (em caso X for maior que o número de respostas, nada será retornado. O valor padrão será usado). | Não |
| Valor padrão | Valor padrão retornado quando não houver correspondência. Também retorna se a árvore não tiver um valor e opção para fragmento não selecionada. | Não |
| Lista de alias namespaces | Lista de aliases que você quer usar para analisar o documento, uma linha por declaração. Você deve especificá-los como prefix=namespace. Esta implementação facilita a utilização de namespace em comparação com versões anteriores do XPathExtractor. | Não |
<?xml version="1.0" encoding="UTF-8"?>
<book>
<title>El guardián entre el centeno</title>
<author>J.D. Salinger</author>
<publisher>Alianza Editorial</publisher>
<year>1951</year>
<genre>Ficción</genre>
<price>10.99</price>
</book>
Podemos extrair os seguintes valores usando XPath:
/book/title //El guardián entre el centeno
/book/author //J.D. Salinger
/book/publisher //Alianza Editorial
/book/year //1951
/book/genre //Ficción
/book/price //10.99
O que é uma Consulta XPath? #
Uma consulta XPath é um expressão escrita no idioma XPath usada para selecionar específicos nós de um documento XML. Expressões XPath são compostas por uma série de passos de localização que especificam como navegar o documento XML e selecionar os nós desejados. Por exemplo, uma simples consulta XPath como //title selecionaria todos os nós titulos no documento XML, enquanto uma consulta mais complexa como //book[@category=‘science’]/title selecionaria apenas os titulos dos livros que pertencem à categoria sciences.
O que outros exemplos de uso poderiam ter o extrator XPath? #
Suponhamos que considere um exemplo mais complexo como o seguinte:
<root>
<item>
<name>John Doe</name>
<age>35</age>
<address>
<street>123 Main St</street>
<city>Anytown</city>
<state>WA</state>
</address>
<phoneNumbers>
<item>
<type>mobile</type>
<number>555-551-1234</number>
</item>
<item>
<type>home</type>
<number>555-552-5678</number>
</item>
</phoneNumbers>
<email>john.doe@example.com</email>
</item>
<item>
<name>Peter Doe</name>
<age>34</age>
<address>
<street>123 Second St</street>
<city>RacconCity</city>
<state>TX</state>
</address>
<phoneNumbers>
<item>
<type>mobile</type>
<number>555-553-1234</number>
</item>
<item>
<type>home</type>
<number>555-554-5678</number>
</item>
</phoneNumbers>
<email>peter.doe@example.com</email>
</item>
<item>
<name>Rick Doe</name>
<age>36</age>
<address>
<street>123 Third St</street>
<city>Springfield</city>
<state>NJ</state>
</address>
<phoneNumbers>
<item>
<type>mobile</type>
<number>555-555-1234</number>
</item>
<item>
<type>home</type>
<number>555-556-5678</number>
</item>
</phoneNumbers>
<email>rick.doe@example.com</email>
</item>
</root>
| XPath Expression | result |
|---|---|
| //name | Todos os elementos de nome: John Doe, Peter Doe, Rick Doe. |
| //item[1]/name | O elemento de nome da primeira entidade: John Doe. |
| //item[2]/age | A propriedade de idade do segundo objeto: 34. |
| //item[3]/email | A propriedade de email do terceiro objeto: rick.doe@example.com |
| //item[1]/address/street | O atributo street da entidade de endereço: 123 Main St. |
| //item[2]/address/city | O atributo city da entidade de endereço: RacconCity. |
| //item[3]/address/state | O atributo state do terceiro objeto de endereço: NJ |
| //item[2]/phoneNumbers/item[type=‘mobile’]/number | Os números móveis da segunda entidade: 555-551-1234, 555-553-1234, 555-555-1234 |
| //item[3]/phoneNumbers/item[type=‘home’]/number | Os números de linha fixa da terceira entidade: 555-556-5678 |
| //phoneNumbers/item[type=‘mobile’]/number | Todos os números móveis: 555-551-1234, 555-553-1234, 555-555-1234 |
| /count(/root/item) | O número de objetos: 3 |
| /sum(//age) | A soma de todas as idades: 105 |
| //name | //email | Todos os nomes e endereços de email. |
| /(//phoneNumbers/item[type=‘mobile’]/number)[1] | O primeiro número móvel: 555-551-1234 |
| /(//phoneNumbers/item[type=‘home’]/number)[2] | O segundo número de linha fixa. |
| //*[starts-with(name(), ‘a’)] | Retorna campos que começam com a letra ‘a’. |
| /(//phoneNumbers/item[starts-with(type, ‘h’)]/number) | Retorna números de telefone cujo tipo começa com ‘h’ - home. |
| /root/item[not(starts-with(email, ‘john’))]/email | Todos os e-mails que não começam com ‘John’. |
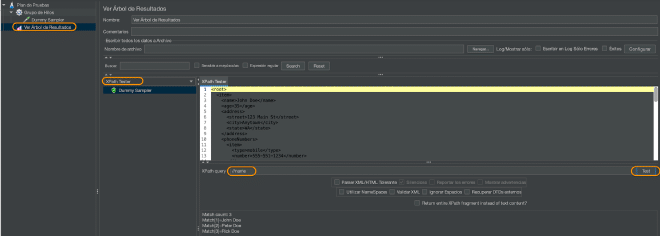
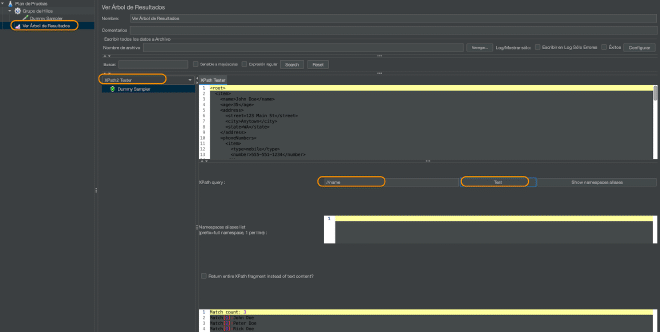
Para avaliar essas afirmações, recomendo usar um Recebedor de Resultados da Visualização e utilizar a visualização em Tester XPath e inserir a afirmação no campo Expressão XPath e clicar no botão Test.
O que é XPath 2 em JMeter? #
Em JMeter, o XPath 2 é implementado usando a biblioteca Saxon, que é uma versão do XPath 2 e XSLT 2. A partir da versão 5 de JMeter, apenas precisamos usar o XPath 2. O principal diferencial entre XPath e XPath 2 em JMeter é que o XPath 2 é uma nova versão do linguagem de consulta XPath e oferece funcionalidades adicionais não disponíveis na versão anterior. Uma das melhorias significativas no XPath 2 é suporte para tipos de dados complexos, permitindo trabalhar com mais dados estruturados em consultas. O XPath 2 também fornece uma série de funções adicionais para manipular e transformar os dados, como ordenação e agrupamento dos resultados da consulta.
XPath 2 Expressões:
| Expressão XPath 2 | Resultado |
|---|---|
| //item[position() = 1] | Seleciona o primeiro item elemento. |
| //phoneNumbers/item[type = ‘home’]/number | Seleciona a número de telefone de todos os elementos que têm um atributo type igual a home. |
| //address[state = ‘WA’]/city | Seleciona a cidade de todos os endereços que têm um atributo state igual a WA. |
| //item[ends-with(email, 'example.com')]/name | Selects the name of all item elements whose email address ends with example.com. |
| //item[name = 'Peter Doe']/address/city | Selects the city from the address of the item item with the name Peter Doe. |
| //phoneNumbers/item[matches(number, '.*1234')]/type | Selects the type of all items whose phone number contains the sequence 1234. |
| //item[age >= 35]/name | Selects the name of all items whose age is greater than or equal to 35. |
| //item[not(address/state = 'TX')]/email | Selects the email address for all items whose status is not TX. |
| //item[phoneNumbers/item[type = 'home'] and phoneNumbers/item[type = 'mobile']]/email | Selects the email address for phones with type home or mobile. |
Conclusão #
O Extrator XPath 2 é um ferramenta muito poderosa para extrair valores, múltiplos valores, avaliações ou execução de funções dos valores para satisfazer uma ou mais condições. Lembre-se sempre de praticar antes de desenvolver sua frase ou expressão. É bom verificar as críticas com diferentes tipos de respostas para obter resultados conclusivos. A prática é necessária, até a próxima!